


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
GON4L (NM_001282860) Human Tagged ORF Clone
CAT#: RG240240
- TrueORF®
GON4L (GFP-tagged) - Human gon-4-like (C. elegans) (GON4L), transcript variant 3
Product Images

Other products for "GON4L"
Specifications
| Product Data | |
| Tag | TurboGFP |
| Symbol | GON4L |
| Synonyms | GON-4; GON4; YARP |
| Vector | pCMV6-AC-GFP |
| E. coli Selection | Ampicillin (100 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RG240240 representing NM_001282860.
Blue=ORF Red=Cloning site Green=Tag(s) GCTCGTTTAGTGAACCGTCAGAATTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTG GATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCC ATGTTGCCCTGTAAGAAGAGAAGAACTACAGTGACAGAGTCCCTACAGCATAAAGGCAATCAAGAGGAA AACAACGTAGACCTAGAATCAGCCGTTAAACCAGAATCTGACCAGGTTAAGGACTTGAGTTCGGTGTCA CTATCCTGGGATCCAAGTCATGGCAGAGTAGCTGGCTTCGAAGTACAGTCTTTGCAGGATGCAGGAAAT CAGCTTGGTATGGAGGATACATCTCTGAGCTCTGGAATGCTCACCCAGAACACAAATGTACCAATTCTA GAAGGTGTTGATGTGGCCATCTCTCAGGGAATCACCCTACCTTCCTTGGAGTCTTTTCACCCCCTTAAT ATACACATTGGTAAAGGAAAACTCCACGCTACTGGCTCAAAGAGAGGGAAAAAAATGACACTCAGGCCT GGGCCAGTTACCCAAGAAGACAGATGTGATCATCTTACCCTAAAGGAGCCTTTTTCAGGAGAGCCTAGT GAAGAAGTCAAGGAAGAAGGAGGGAAACCTCAAATGAATTCTGAAGGGGAGATACCTTCCCTGCCATCA GGCAGCCAATCTGCAAAACCAGTAAGCCAGCCCAGGAAATCAACCCAGCCAGATGTTTGTGCCTCTCCT CAAGAAAAGCCACTCAGGACTCTGTTTCACCAACCTGAGGAAGAGATAGAAGATGGTGGACTCTTCATT CCAATGGAAGAACAAGACAATGAAGAAAGTGAGAAAAGGAGAAAAAAGAAAAAGGGTACCAAGAGGAAA CGAGATGGAAGGGGTCAAGAAGGGACCTTGGCATATGACCTGAAACTGGATGACATGCTTGACCGTACC TTGGAGGATGGTGCCAAGCAGCACAATCTAACAGCAGTCAATGTCCGAAACATCCTTCATGAAGTAATC ACAAATGAACACGTGGTAGCTATGATGAAAGCAGCCATCAGTGAGACGGAAGATATGCCAATGTTTGAG CCTAAAATGACACGCTCTAAACTGAAGGAAGTAGTGGAAAAAGGAGTGGTAATTCCAACATGGAATATT TCACCAATTAAGAAGGCCAATGAAATTAAGCCTCCTCAGTTTGTGGATATCCACCTTGAAGAAGATGAT TCCTCAGATGAAGAATACCAGCCGGATGATGAAGAAGAAGATGAAACTGCTGAAGAGAGCTTATTGGAA AGTGATGTTGAAAGCACTGCTTCATCTCCACGTGGGGCAAAGAAATCCAGATTGAGGCAGTCTTCTGAG ATGACTGAAACAGATGAGGAGAGTGGCATATTATCAGAGGCTGAGAAAGTCACCACACCAGCCATCAGG CACATCAGTGCTGAGGTAGTGCCCATGGGGCCCCCGCCCCCTCCAAAGCCGAAACAGACCAGAGATAGT ACTTTCATGGAGAAGTTACATGCGGTAGATGAGGAGCTGGCTTCCAGTCCAGTCTGCATGGATTCTTTC CAGCCCATGGATGACAGTCTCATTGCATTTCGAACGCGTTCTAAGATGCCCCTGAAAGATGTTCCCCTG GGCCAATTAGAGGCAGAGCTCCAAGCTCCAGACATCACTCCAGATATGTATGACCCCAATACGGCAGAT GATGAGGACTGGAAGATGTGGCTGGGGGGACTTATGAATGATGATGTGGGGAATGAAGATGAAGCAGAT GATGATGATGATCCAGAATATAATTTCCTGGAAGACCTCGATGAACCAGACACAGAGGATTTCCGGACT GACCGGGCAGTGAGAATCACCAAAAAGGAAGTAAATGAGCTGATGGAAGAGCTGTTTGAAACTTTCCAA GATGAGATGGGATTCTCCAACATGGAAGATGATGGCCCAGAAGAGGAGGAGTGTGTAGCTGAGCCTCGT CCTAACTTTAACACCCCTCAAGCTCTACGGTTTGAGGAACCACTGGCCAACCTGTTAAATGAACAACAT CGGACAGTGAAGGAGCTATTTGAACAGCTGAAGATGAAGAAATCTTCAGCCAAACAGCTGCAGGAAGTA GAGAAGGTTAAACCCCAGAGTGAGAAAGTTCATCAGACTCTGATTCTGGACCCAGCACAGAGGAAGAGA CTCCAGCAGCAGATGCAGCAGCACGTTCAGCTCTTGACCCAAATCCACCTTCTTGCCACCTGCAACCCC AACCTCAATCCGGAGGCCACTACCACCAGGATATTTCTTAAAGAGCTGGGAACCTTTGCTCAAAGCTCC ATCGCCCTTCACCATCAGTACAACCCCAAGTTTCAGACCCTGTTCCAACCCTGTAACTTGATGGGAGCT ATGCAGCTGATTGAAGACTTCAGCACACATGTCAGCATTGACTGCAGCCCTCATAAAACTGTCAAGAAG ACTGCGAATGAATTTCCCTGTTTGCCAAAGCAAGTGGCTTGGATTCTGGCCACAAGCAAGGTTTTCATG TATCCAGAGTTACTTCCAGTGTGTTCCCTGAAGGCAAAGAATCCCCAGGATAAGATCGTCTTCACCAAG GCTGAGGACAATTTGTTAGCTTTAGGACTGAAGCATTTTGAAGGAACTGAGTTTCCTAATCCTCTAATC AGCAAGTACCTTCTAACCTGCAAAACTGCCCACCAACTGACAGTGAGAATCAAGAACCTCAACATGAAC AGAGCTCCTGACAACATCATTAAATTTTATAAGAAGACCAAACAGCTGCCAGTCCTAGGAAAATGCTGT GAAGAGATCCAGCCACATCAGTGGAAGCCACCTATAGAGAGAGAAGAACACCGGCTCCCATTCTGGTTA AAGGCCAGTCTGCCATCCATCCAGGAAGAACTGCGGCACATGGCTGATGGTGCTAGAGAGGTAGGAAAT ATGACTGGAACCACTGAGATCAACTCAGATCGAAGCCTAGAAAAAGACAATTTGGAGTTGGGGAGTGAA TCTCGGTACCCACTGCTATTGCCTAAGGGTGTAGTCCTGAAACTGAAGCCAGTTGCCACCCGTTTCCCC AGGAAGGCTTGGAGACAGAAGCGTTCATCAGTCCTGAAGCCCCTCCTTATCCAACCCAGCCCCTCTCTC CAGCCCAGCTTCAACCCTGGGAAAACACCAGCCCGATCAACTCATTCAGAAGCCCCTCCGAGCAAAATG GTGCTCCGGATTCCTCACCCAATACAGCCAGCCACTGTTTTACAGACAGTTCCAGGTGTCCCTCCACTG GGGGTCAGTGGAGGTGAGAGTTTTGAGTCTCCTGCAGCACTGCCTGCTGTGCCCCCTGAGGCCAGGACA AGCTTCCCTCTGTCTGAGTCCCAGACTTTGCTCTCTTCTGCCCCTGTGCCCAAGGTAATGCTGCCCTCC CTTGCCCCTTCTAAGTTTCGAAAGCCATATGTGAGACGGAGACCCTCAAAGAGAAGAGGAGTCAAGGCC TCTCCCTGTATGAAACCTGCCCCTGTTATCCACCACCCTGCATCTGTTATCTTCACTGTTCCTGCTACC ACTGTGAAGATTGTGAGCCTTGGCGGTGGCTGTAACATGATCCAGCCTGTCAATGCGGCTGTGGCCCAG AGTCCCCAGACTATTCCCATCACTACCCTCTTGGTTAACCCTACTTCCTTCCCCTGTCCATTGAACCAG TCCCTTGTGGCCTCCTCTGTCTCACCCTTAATTGTTTCTGGCAATTCTGTGAATCTTCCTATACCATCC ACCCCTGAAGATAAGGCCCACGTGAATGTGGACATTGCTTGTGCTGTGGCTGATGGGGAAAATGCCTTT CAGGGCCTAGAACCCAAATTAGAGCCCCAGGAACTATCTCCTCTCTCTGCTACTGTTTTCCCGAAAGTG GAACATAGCCCAGGGCCTCCACTAGCAGATGCAGAGTGCCAAGAAGGATTGTCAGAGAATAGTGCCTGT CGCTGGACCGTTGTGAAAACAGAGGAGGGGAGGCAAGCTCTGGAGCCGCTCCCTCAGGGCATCCAGGAG TCTCTAAACAACCCTACCCCTGGGGATTTAGAGGAAATTGTCAAGATGGAACCTGAAGAAGCTAGAGAG GAAATCAGTGGATCCCCTGAGCGTGATATTTGTGATGACATCAAAGTGGAACATGCTGTGGAATTGGAC ACTGGTGCCCCAAGCGAGGAGTTGAGCAGTGCTGGAGAAGTAACGAAACAGACAGTCTTACAGAAGGAA GAGGAGAGGAGTCAGCCAACTAAAACCCCTTCATCTTCTCAAGAGCCCCCTGATGAAGGAACCTCAGGG ACAGATGTGAACAAAGGATCATCAAAGAATGCTTTGTCCTCAATGGATCCTGAAGTGAGGCTTAGTAGC CCCCCAGGGAAGCCAGAAGATTCATCCAGTGTTGATGGTCAGTCAGTGGGGACTCCAGTTGGGCCAGAA ACTGGAGGAGAGAAGAATGGGCCAGAAGAAGAGGAAGAAGAGGACTTTGATGACCTCACCCAAGATGAG GAAGATGAAATGTCATCAGCTTCTGAGGAATCTGTGCTTTCTGTCCCAGAACTCCAGGAAACAATGGAG AAACTGACTTGGCTGGCATCTGAAAGGCGCATGAGTCAGGAGGGTGAGTCTGAAGAAGAGAATTCTCAG GAGGAGAACTCTGAGCCAGAAGAAGAGGAGGAAGAAGAAGCAGAAGGAATGGAAAGCCTGCAGAAAGAG GATGAAATGACGGATGAAGCAGTTGGAGACTCTGCTGAGAAGCCTCCTACTTTTGCTTCACCTGAGACT GCTCCAGAAGTGGAGACCAGCAGAACTCCACCAGGAGAGAGCATCAAAGCTGCTGGAAAAGGCCGGAAC AATCATCGAGCTCGCAACAAGCGGGGAAGTCGGGCTCGGGCCAGCAAGGACACCTCCAAGCTGCTGTTG CTGTATGATGAGGACATTCTCGAGCGAGATCCACTCAGGGAGCAGAAGGACTTGGCCTTTGCCCAAGCT TATCTGACCAGGGTGCGAGAAGCCCTACAACATATCCCTGGCAAGTATGAAGACTTCCTTCAAGTCATC TATGAATTTGAGTCAAGTACCCAGAGACGGACGGCTGTAGATCTCTACAAAAGCCTGCAAATTCTGCTC CAAGACTGGCCTCAGCTGTTGAAAGACTTTGCTGCTTTCCTGTTACCTGAGCAAGCTCTGGCCTGTGGA TTATTTGAGGAGCAGCAGGCTTTTGAGAAGAGCCGCAAGTTCCTTCGGCAGCTGGAGATTTGCTTTGCA GAGAACCCCTCACACCACCAGAAGATTATCAAGGTCCTCCAAGGCTGTGCAGACTGCCTTCCCCAGGAG ATCACCGAGCTCAAGACACAGATGTGGCAGCTCCTCAAGGGCCACGACCACCTGCAGGATGAGTTTTCT ATCTTCTTTGACCACTTGCGCCCAGCAGCTAGCCGGATGGGTGACTTTGAAGAGATCAATTGGACTGAG GAAAAGGAGTATGAGTTTGATGGCTTTGAAGAAGTGGCCCTGCCTGATGTGGAAGAAGAGGAGGAGCCT CCCAAGATACCCACAGCCTCAAAGAACAAGAGGAAAAAAGAGATCGGGGTCCAAAATCATGATAAGGAG ACTGAATGGCCAGATGGGGCCAAGGACTGTGCCTGCTCCTGCCATGAAGGAGGTCCAGATTCCAAGCTG AAGAAGAGCAAAAGGCGGAGCTGTAGCCACTGTAGCAGCAAGGTCTGTGACAGCAAATCCTACAAGAGC AAGGAGCCCCATGAGTTGGTGGGCAGCAGCCCCCACCGAGAGGCTAGTCCTATGCCTGGTGCTAAGGAA GCTGGGCAGGGCAAGGATATGATGGAAGAGGAAGCCCCAGAGGAGCGGGAGAGCACTGAGGCCACCCAG AGCAGGACTGTCAGGACCACCAGAAAGGGAGAGATGCCTGTTTCAGCAGGATTGGCAGTGGGGAGCACT TTGCCATCCCCTCGAGAAGTGACTGTTACAGAACGGCTCCTCCTGGATGGCCCACCACCTCATTCACCA GAGACTCCTCAATTTCCCCCCACAACTGGAGCTGTACTGTACACTGTTAAGAGAAACCAGGTTGGGCCT GAGGTTCGCTCCTGCCCCAAGGCATCCCCCAGACTTCAGAAAGAGAGGGAGGGCCAAAAGGCAGTGAGT GAGTCAGAGGCTTTGATGCTGGTCTGGGATGCATCAGAAACTGAGAAATTGCCTGGTACCGTGGAACCC CCTGCTTCCTTCCTGAGTCCTGTTTCCTCAAAGACCAGAGATGCAGGGAGAAGACATGTGTCCGGGAAA CCAGACACTCAAGAGAGATGGCTGCCCTCAAGCAGAGCTCGGGTGAAGACAAGAGACAGGACGTGCCCT GTCCATGAATCTCCATCAGGAATTGACACCTCAGAGACTTCTCCCAAAGCCCCTAGAGGGGGTTTGGCT AAAGACAGTGGAACACAGGCCAAGGGTCCAGAGGGGGAGCAGCAGCCAAAGGCCGCAGAAGCTACGGTG TGTGCCAACAACAGCAAGGTCAGCTCCACTGGGGAAAAGGTTGTCCTGTGGACAAGGGAAGCTGACCGT GTGATCCTCACCATGTGCCAGGAGCAAGGGGCACAGCCACAGACCTTCAACATCATCTCCCAGCAGCTG GGAAATAAGACCCCTGCTGAGGTTTCCCACCGTTTTCGAGAACTCATGCAGCTCTTCCACACTGCCTGT GAAGCCAGCTCTGAGGATGAGGATGATGCAACCAGTACCAGCAATGCAGACCAGCTGTCTGACCATGGG GACCTTCTGTCTGAAGAGGAGCTGGATGAA AGCGGACCGACGCGTACGCGGCCGCTCGAG - GFP Tag - GTTTAAAC >Peptide sequence encoded by RG240240
Blue=ORF Red=Cloning site Green=Tag(s) MLPCKKRRTTVTESLQHKGNQEENNVDLESAVKPESDQVKDLSSVSLSWDPSHGRVAGFEVQSLQDAGN QLGMEDTSLSSGMLTQNTNVPILEGVDVAISQGITLPSLESFHPLNIHIGKGKLHATGSKRGKKMTLRP GPVTQEDRCDHLTLKEPFSGEPSEEVKEEGGKPQMNSEGEIPSLPSGSQSAKPVSQPRKSTQPDVCASP QEKPLRTLFHQPEEEIEDGGLFIPMEEQDNEESEKRRKKKKGTKRKRDGRGQEGTLAYDLKLDDMLDRT LEDGAKQHNLTAVNVRNILHEVITNEHVVAMMKAAISETEDMPMFEPKMTRSKLKEVVEKGVVIPTWNI SPIKKANEIKPPQFVDIHLEEDDSSDEEYQPDDEEEDETAEESLLESDVESTASSPRGAKKSRLRQSSE MTETDEESGILSEAEKVTTPAIRHISAEVVPMGPPPPPKPKQTRDSTFMEKLHAVDEELASSPVCMDSF QPMDDSLIAFRTRSKMPLKDVPLGQLEAELQAPDITPDMYDPNTADDEDWKMWLGGLMNDDVGNEDEAD DDDDPEYNFLEDLDEPDTEDFRTDRAVRITKKEVNELMEELFETFQDEMGFSNMEDDGPEEEECVAEPR PNFNTPQALRFEEPLANLLNEQHRTVKELFEQLKMKKSSAKQLQEVEKVKPQSEKVHQTLILDPAQRKR LQQQMQQHVQLLTQIHLLATCNPNLNPEATTTRIFLKELGTFAQSSIALHHQYNPKFQTLFQPCNLMGA MQLIEDFSTHVSIDCSPHKTVKKTANEFPCLPKQVAWILATSKVFMYPELLPVCSLKAKNPQDKIVFTK AEDNLLALGLKHFEGTEFPNPLISKYLLTCKTAHQLTVRIKNLNMNRAPDNIIKFYKKTKQLPVLGKCC EEIQPHQWKPPIEREEHRLPFWLKASLPSIQEELRHMADGAREVGNMTGTTEINSDRSLEKDNLELGSE SRYPLLLPKGVVLKLKPVATRFPRKAWRQKRSSVLKPLLIQPSPSLQPSFNPGKTPARSTHSEAPPSKM VLRIPHPIQPATVLQTVPGVPPLGVSGGESFESPAALPAVPPEARTSFPLSESQTLLSSAPVPKVMLPS LAPSKFRKPYVRRRPSKRRGVKASPCMKPAPVIHHPASVIFTVPATTVKIVSLGGGCNMIQPVNAAVAQ SPQTIPITTLLVNPTSFPCPLNQSLVASSVSPLIVSGNSVNLPIPSTPEDKAHVNVDIACAVADGENAF QGLEPKLEPQELSPLSATVFPKVEHSPGPPLADAECQEGLSENSACRWTVVKTEEGRQALEPLPQGIQE SLNNPTPGDLEEIVKMEPEEAREEISGSPERDICDDIKVEHAVELDTGAPSEELSSAGEVTKQTVLQKE EERSQPTKTPSSSQEPPDEGTSGTDVNKGSSKNALSSMDPEVRLSSPPGKPEDSSSVDGQSVGTPVGPE TGGEKNGPEEEEEEDFDDLTQDEEDEMSSASEESVLSVPELQETMEKLTWLASERRMSQEGESEEENSQ EENSEPEEEEEEEAEGMESLQKEDEMTDEAVGDSAEKPPTFASPETAPEVETSRTPPGESIKAAGKGRN NHRARNKRGSRARASKDTSKLLLLYDEDILERDPLREQKDLAFAQAYLTRVREALQHIPGKYEDFLQVI YEFESSTQRRTAVDLYKSLQILLQDWPQLLKDFAAFLLPEQALACGLFEEQQAFEKSRKFLRQLEICFA ENPSHHQKIIKVLQGCADCLPQEITELKTQMWQLLKGHDHLQDEFSIFFDHLRPAASRMGDFEEINWTE EKEYEFDGFEEVALPDVEEEEEPPKIPTASKNKRKKEIGVQNHDKETEWPDGAKDCACSCHEGGPDSKL KKSKRRSCSHCSSKVCDSKSYKSKEPHELVGSSPHREASPMPGAKEAGQGKDMMEEEAPEERESTEATQ SRTVRTTRKGEMPVSAGLAVGSTLPSPREVTVTERLLLDGPPPHSPETPQFPPTTGAVLYTVKRNQVGP EVRSCPKASPRLQKEREGQKAVSESEALMLVWDASETEKLPGTVEPPASFLSPVSSKTRDAGRRHVSGK PDTQERWLPSSRARVKTRDRTCPVHESPSGIDTSETSPKAPRGGLAKDSGTQAKGPEGEQQPKAAEATV CANNSKVSSTGEKVVLWTREADRVILTMCQEQGAQPQTFNIISQQLGNKTPAEVSHRFRELMQLFHTAC EASSEDEDDATSTSNADQLSDHGDLLSEEELDE SGPTRTRPLEMESDESGLPAMEIECRITGTLNGVEFELVGGGEGTPEQGRMTNKMKSTKGALTFSPYLL SHVMGYGFYHFGTYPSGYENPFLHAINNGGYTNTRIEKYEDGGVLHVSFSYRYEAGRVIGDFKVMGTGF PEDSVIFTDKIIRSNATVEHLHPMGDNDLDGSFTRTFSLRDGGYYSSVVDSHMHFKSAIHPSILQNGGP MFAFRRVEEDHSNTELGIVEYQHAFKTPDADAGEERV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
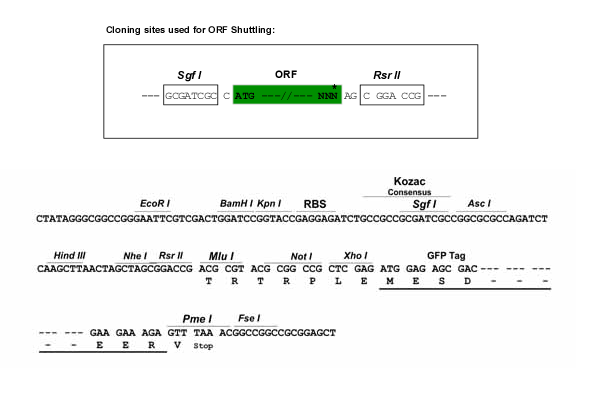
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_001282860 |
| ORF Size | 6723 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified, transfection-ready dried plasmid DNA, and shipped with 2 vector sequencing primers. |
| Reference Data | |
| RefSeq | NM_001282860.2 |
| RefSeq Size | 7833 bp |
| RefSeq ORF | 6726 bp |
| Locus ID | 54856 |
| Cytogenetics | 1q22 |
| MW | 249.1 kDa |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
{0} Product Review(s)
0 Product Review(s)
Submit review
Be the first one to submit a review

Product Citations
*Delivery time may vary from web posted schedule. Occasional delays may occur due to unforeseen
complexities in the preparation of your product. International customers may expect an additional 1-2 weeks
in shipping.