


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
CACNA1H (NM_021098) Human Tagged ORF Clone
CAT#: RC212772

CACNA1H (Myc-DDK-tagged)-Human calcium channel, voltage-dependent, T type, alpha 1H subunit (CACNA1H), transcript variant 1
"NM_021098" in other vectors (3)
Product Images
 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC212772 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | CACNA1H |
| Synonyms | CACNA1HB; Cav3.2; ECA6; EIG6; HALD4 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC212772 representing NM_021098
Red=Cloning site Blue=ORF Green=Tags(s) GCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCCGGCGCGCCAGATCTC AAGCTTAACTAGCTAGCGGACCGAC ATGACCGAGGGCGCACGGGCCGCCGACGAGGTCCGGGTGCCCCTGGGCGCGCCGCCCCCTGGCCCTGCGG CGTTGGTGGGGGCGTCCCCGGAGAGCCCCGGGGCGCCGGGACGCGAGGCGGAGCGGGGGTCCGAGCTCGG CGTGTCACCCTCCGAGAGCCCGGCGGCCGAGCGCGGCGCGGAGCTGGGTGCCGACGAGGAGCAGCGCGTC CCGTACCCGGCCTTGGCGGCCACGGTCTTCTTCTGCCTCGGTCAGACCACGCGGCCGCGCAGCTGGTGCC TCCGGCTGGTCTGCAACCCATGGTTCGAGCACGTGAGCATGCTGGTAATCATGCTCAACTGCGTGACCCT GGGCATGTTCCGGCCCTGTGAGGACGTTGAGTGCGGCTCCGAGCGCTGCAACATCCTGGAGGCCTTTGAC GCCTTCATTTTCGCCTTTTTTGCGGTGGAGATGGTCATCAAGATGGTGGCCTTGGGGCTGTTCGGGCAGA AGTGTTACCTGGGTGACACGTGGAACAGGCTGGATTTCTTCATCGTCGTGGCGGGCATGATGGAGTACTC GTTGGACGGACACAACGTGAGCCTCTCGGCTATCAGGACCGTGCGGGTGCTGCGGCCCCTCCGCGCCATC AACCGCGTGCCTAGCATGCGGATCCTGGTCACTCTGCTGCTGGATACGCTGCCCATGCTCGGGAACGTCC TTCTGCTGTGCTTCTTCGTCTTCTTCATTTTCGGCATCGTTGGCGTCCAGCTCTGGGCTGGCCTCCTGCG GAACCGCTGCTTCCTGGACAGTGCCTTTGTCAGGAACAACAACCTGACCTTCCTGCGGCCGTACTACCAG ACGGAGGAGGGCGAGGAGAACCCGTTCATCTGCTCCTCACGCCGAGACAACGGCATGCAGAAGTGCTCGC ACATCCCCGGCCGCCGCGAGCTGCGCATGCCCTGCACCCTGGGCTGGGAGGCCTACACGCAGCCGCAGGC CGAGGGGGTGGGCGCTGCACGCAACGCCTGCATCAACTGGAACCAGTACTACAACGTGTGCCGCTCGGGT GACTCCAACCCCCACAACGGTGCCATCAACTTCGACAACATCGGCTACGCCTGGATTGCCATCTTCCAGG TGATCACGCTGGAAGGCTGGGTGGACATCATGTACTACGTCATGGACGCCCACTCATTCTACAACTTCAT CTATTTCATCCTGCTCATCATCGTGGGCTCCTTCTTCATGATCAACCTGTGCCTGGTGGTGATTGCCACG CAGTTCTCGGAGACGAAGCAGCGGGAGAGTCAGCTGATGCGGGAGCAGCGGGCACGCCACCTGTCCAACG ACAGCACGCTGGCCAGCTTCTCCGAGCCTGGCAGCTGCTACGAAGAGCTGCTGAAGTACGTGGGCCACAT ATTCCGCAAGGTCAAGCGGCGCAGCTTGCGCCTCTACGCCCGCTGGCAGAGCCGCTGGCGCAAGAAGGTG GACCCCAGTGCTGTGCAAGGCCAGGGTCCCGGGCACCGCCAGCGCCGGGCAGGCAGGCACACAGCCTCGG TGCACCACCTGGTTTACCACCACCATCACCACCACCACCACCACTACCATTTCAGCCATGGCAGCCCCCG CAGGCCCGGCCCCGAGCCAGGCGCCTGCGACACCAGGCTGGTCCGAGCTGGCGCGCCCCCCTCGCCACCT TCCCCAGGCCGCGGACCCCCCGACGCAGAGTCTGTGCACAGCATCTACCATGCCGACTGCCACATAGAGG GGCCGCAGGAGAGGGCCCGGGTGGCACATGCCGCAGCCACTGCCGCTGCCAGCCTCAGACTGGCCACAGG GCTGGGCACCATGAACTACCCCACGATCCTGCCCTCAGGGGTGGGCAGCGGCAAAGGCAGCACCAGCCCC GGACCCAAGGGGAAGTGGGCCGGTGGACCGCCAGGCACCGGGGGGCACGGCCCGTTGAGCTTGAACAGCC CTGATCCCTACGAGAAGATCCCGCATGTGGTCGGGGAGCATGGACTGGGCCAGGCCCCTGGCCATCTGTC GGGCCTCAGTGTGCCCTGCCCCCTGCCCAGCCCCCCAGCGGGCACACTGACCTGTGAGCTGAAGAGCTGC CCGTACTGCACCCGTGCCCTGGAGGACCCGGAGGGTGAGCTCAGCGGCTCGGAAAGTGGAGACTCAGATG GCCGTGGCGTCTATGAATTCACGCAGGACGTCCGGCACGGTGACCGCTGGGACCCCACGCGACCACCCCG TGCGACGGACACACCAGGCCCAGGCCCAGGCAGCCCCCAGCGGCGGGCACAGCAGAGGGCAGCCCCGGGC GAGCCAGGCTGGATGGGCCGCCTCTGGGTTACCTTCAGCGGCAAGCTGCGCCGCATCGTGGACAGCAAGT ACTTCAGCCGTGGCATCATGATGGCCATCCTTGTCAACACGCTGAGCATGGGCGTGGAGTACCATGAGCA GCCCGAGGAGCTGACTAATGCTCTGGAGATCAGCAACATCGTGTTCACCAGCATGTTTGCCCTGGAGATG CTGCTGAAGCTGCTGGCCTGCGGCCCTCTGGGCTACATCCGGAACCCGTACAACATCTTCGACGGCATCA TCGTGGTCATCAGCGTCTGGGAGATCGTGGGGCAGGCGGACGGTGGCTTGTCTGTGCTGCGCACCTTCCG GCTGCTGCGTGTGCTGAAGCTGGTGCGCTTTCTGCCAGCCCTGCGGCGCCAGCTCGTGGTGCTGGTGAAG ACCATGGACAACGTGGCTACCTTCTGCACGCTGCTCATGCTCTTCATTTTCATCTTCAGCATCCTGGGCA TGCACCTTTTCGGCTGCAAGTTCAGCCTGAAGACAGACACCGGAGACACCGTGCCTGACAGGAAGAACTT CGACTCCCTGCTGTGGGCCATCGTCACCGTGTTCCAGATCCTGACCCAGGAGGACTGGAACGTGGTCCTG TACAACGGCATGGCCTCCACCTCCTCCTGGGCCGCCCTCTACTTCGTGGCCCTCATGACCTTCGGCAACT ATGTGCTCTTCAACCTGCTGGTGGCCATCCTCGTGGAGGGCTTCCAGGCGGAGGGCGATGCCAACAGATC CGACACGGACGAGGACAAGACGTCGGTCCACTTCGAGGAGGACTTCCACAAGCTCAGAGAACTCCAGACC ACAGAGCTGAAGATGTGTTCCCTGGCCGTGACCCCCAACGGGCACCTGGAGGGACGAGGCAGCCTGTCCC CTCCCCTCATCATGTGCACAGCTGCCACGCCCATGCCTACCCCCAAGAGCTCACCATTCCTGGATGCAGC CCCCAGCCTCCCAGACTCTCGGCGTGGCAGCAGCAGCTCCGGGGACCCGCCACTGGGAGACCAGAAGCCT CCGGCCAGCCTCCGAAGTTCTCCCTGTGCCCCCTGGGGCCCCAGTGGCGCCTGGAGCAGCCGGCGCTCCA GCTGGAGCAGCCTGGGCCGTGCCCCCAGCCTCAAGCGCCGCGGCCAGTGTGGGGAACGTGAGTCCCTGCT GTCTGGCGAGGGCAAGGGCAGCACCGACGACGAAGCTGAGGACGGCAGGGCCGCGCCCGGGCCCCGTGCC ACCCCACTGCGGCGGGCCGAGTCCCTGGACCCACGGCCCCTGCGGCCGGCCGCCCTCCCGCCTACCAAGT GCCGCGATCGCGACGGGCAGGTGGTGGCCCTGCCCAGCGACTTCTTCCTGCGCATCGACAGCCACCGTGA GGATGCAGCCGAGCTTGACGACGACTCGGAGGACAGCTGCTGCCTCCGCCTGCATAAAGTGCTGGAGCCC TACAAGCCCCAGTGGTGCCGGAGCCGCGAGGCCTGGGCCCTCTACCTCTTCTCCCCACAGAACCGGTTCC GCGTCTCCTGCCAGAAGGTCATCACACACAAGATGTTTGATCACGTGGTCCTCGTCTTCATCTTCCTCAA CTGCGTCACCATCGCCCTGGAGAGGCCTGACATTGACCCCGGCAGCACCGAGCGGGTCTTCCTCAGCGTC TCCAATTACATCTTCACGGCCATCTTCGTGGCAGAGATGATGGTGAAGGTGGTGGCCCTGGGGCTGCTGT CCGGCGAGCACGCCTACCTGCAGAGCAGCTGGAACCTGCTGGATGGGCTGCTGGTGCTGGTGTCCCTGGT GGACATTGTCGTGGCCATGGCCTCGGCTGGTGGCGCCAAGATCCTGGGTGTTCTGCGCGTGCTGCGTCTG CTGCGGACCCTGCGGCCTCTGAGGGTCATCAGCCGGGCCCCGGGCCTCAAGCTGGTGGTGGAGACGCTGA TATCATCACTCAGGCCCATTGGGAACATCGTCCTCATCTGCTGCGCCTTCTTCATCATTTTTGGCATCTT GGGTGTGCAGCTCTTCAAAGGGAAGTTCTACTACTGCGAGGGCCCCGACACCAGGAACATCTCCACCAAG GCACAGTGCCGGGCCGCCCACTACCGCTGGGTGCGACGCAAGTACAACTTCGACAACCTGGGCCAGGCCC TGATGTCGCTGTTCGTGCTGTCATCCAAGGATGGATGGGTGAACATCATGTACGACGGGCTGGATGCCGT GGGTGTCGACCAGCAGCCTGTGCAGAACCACAACCCCTGGATGCTGCTGTACTTCATCTCCTTCCTGCTC ATCGTCAGCTTCTTCGTGCTCAACATGTTCGTGGGCGTCGTGGTCGAGAACTTCCACAAGTGCCGGCAGC ACCAGGAGGCGGAGGAGGCGCGGCGGCGAGAGGAGAAGCGGCTGCGGCGCCTAGAGAGGAGGCGCAGGAG CACTTTCCCCAGCCCAGAGGCCCAGCGCCGGCCCTACTATGCCGACTACTCGCCCACGCGCCGCTCCATT CACTCGCTGTGCACCAGCCACTATCTCGACCTCTTCATCACCTTCATCATCTGTGTCAACGTCATCACCA TGTCCATGGAGCACTATAACCAACCCAAGTCGCTGGACGAGGCCCTCAAGTACTGCAACTACGTCTTCAC CATCGTGTTTGTCTTCGAGGCTGCACTGAAGCTGGTAGCATTTGGGTTCCGTCGGTTCTTCAAGGACAGG TGGAACCAGCTGGACCTGGCCATCGTGCTGCTGTCACTCATGGGCATCACGCTGGAGGAGATAGAGATGA GCGCCGCGCTGCCCATCAACCCCACCATCATCCGCATCATGCGCGTGCTTCGCATTGCCCGTGTGCTGAA GCTGCTGAAGATGGCTACGGGCATGCGCGCCCTGCTGGACACTGTGGTGCAAGCTCTCCCCCAGGTGGGG AACCTGGGCCTTCTTTTCATGCTCCTGTTTTTTATCTATGCTGCGCTGGGAGTGGAGCTGTTCGGGAGGC TGGAGTGCAGTGAAGACAACCCCTGCGAGGGCCTGAGCAGGCACGCCACCTTCAGCAACTTCGGCATGGC CTTCCTCACGCTGTTCCGCGTGTCCACGGGGGACAACTGGAACGGGATCATGAAGGACACGCTGCGCGAG TGCTCCCGTGAGGACAAGCACTGCCTGAGCTACCTGCCGGCCCTGTCGCCCGTCTACTTCGTGACCTTCG TGCTGGTGGCCCAGTTCGTGCTGGTGAACGTGGTGGTGGCCGTGCTCATGAAGCACCTGGAGGAGAGCAA CAAGGAGGCACGGGAGGATGCGGAGCTGGACGCCGAGATCGAGCTGGAGATGGCGCAGGGCCCCGGGAGT GCACGCCGGGTGGACGCGGACAGGCCTCCCTTGCCCCAGGAGAGTCCGGGCGCCAGGGATGCCCCAAACC TGGTTGCACGCAAGGTGTCCGTGTCCAGGATGCTCTCGCTGCCCAACGACAGCTACATGTTCAGGCCCGT GGTGCCTGCCTCGGCGCCCCACCCCCGCCCGCTGCAGGAGGTGGAGATGGAGACCTATGGGGCCGGCACC CCCTTGGGCTCCGTTGCCTCTGTGCACTCTCCGCCCGCAGAGTCCTGTGCCTCCCTCCAGATCCCACTGG CTGTGTCGTCCCCAGCCAGGAGCGGCGAGCCCCTCCACGCCCTGTCCCCTCGGGGCACAGCCCGCTCCCC CAGTCTCAGCCGGCTGCTCTGCAGACAGGAGGCTGTGCACACCGATTCCTTGGAAGGGAAGATTGACAGC CCTAGGGACACCCTGGATCCTGCAGAGCCTGGTGAGAAAACCCCGGTGAGGCCGGTGACCCAGGGGGGCT CCCTGCAGTCCCCACCACGCTCCCCACGGCCCGCCAGCGTCCGCACTCGTAAGCATACCTTCGGACAGCG CTGCGTCTCCAGCCGGCCGGCGGCCCCAGGCGGAGAGGAGGCCGAGGCCTCGGACCCAGCCGACGAGGAG GTCAGCCACATCACCAGCTCCGCCTGCCCCTGGCAGCCCACAGCCGAGCCCCATGGCCCCGAAGCCTCTC CGGTGGCCGGCGGCGAGCGGGACCTGCGCAGGCTCTACAGCGTGGACGCTCAGGGCTTCCTGGACAAGCC GGGCCGGGCAGACGAGCAGTGGCGGCCCTCGGCGGAGCTGGGCAGCGGGGAGCCTGGGGAGGCGAAGGCC TGGGGCCCTGAGGCCGAGCCCGCTCTGGGTGCGCGCAGAAAGAAGAAGATGAGCCCCCCCTGCATCTCGG TGGAACCCCCTGCGGAGGACGAGGGCTCTGCGCGGCCCTCCGCGGCAGAGGGCGGCAGCACCACACTGAG GCGCAGGACCCCGTCCTGTGAGGCCACGCCTCACAGGGACTCCCTGGAGCCCACAGAGGGCTCAGGCGCC GGGGGGGACCCTGCAGCCAAGGGGGAGCGCTGGGGCCAGGCCTCCTGCCGGGCTGAGCACCTGACCGTCC CCAGCTTTGCCTTTGAGCCGCTGGACCTCGGGGTCCCCAGTGGAGACCCTTTCTTGGACGGTAGCCACAG TGTGACCCCAGAATCCAGAGCTTCCTCTTCAGGGGCCATAGTGCCCCTGGAACCCCCAGAATCAGAGCCT CCCATGCCCGTCGGTGACCCCCCAGAGAAGAGGCGGGGGCTGTACCTCACAGTCCCCCAGTGTCCTCTGG AGAAACCAGGGTCCCCCTCAGCCACCCCTGCCCCAGGGGGTGGTGCAGATGACCCCGTG ACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCCTGGATT ACAAGGATGACGACGATAAGGTTTAA >RC212772 representing NM_021098
Red=Cloning site Green=Tags(s) MTEGARAADEVRVPLGAPPPGPAALVGASPESPGAPGREAERGSELGVSPSESPAAERGAELGADEEQRV PYPALAATVFFCLGQTTRPRSWCLRLVCNPWFEHVSMLVIMLNCVTLGMFRPCEDVECGSERCNILEAFD AFIFAFFAVEMVIKMVALGLFGQKCYLGDTWNRLDFFIVVAGMMEYSLDGHNVSLSAIRTVRVLRPLRAI NRVPSMRILVTLLLDTLPMLGNVLLLCFFVFFIFGIVGVQLWAGLLRNRCFLDSAFVRNNNLTFLRPYYQ TEEGEENPFICSSRRDNGMQKCSHIPGRRELRMPCTLGWEAYTQPQAEGVGAARNACINWNQYYNVCRSG DSNPHNGAINFDNIGYAWIAIFQVITLEGWVDIMYYVMDAHSFYNFIYFILLIIVGSFFMINLCLVVIAT QFSETKQRESQLMREQRARHLSNDSTLASFSEPGSCYEELLKYVGHIFRKVKRRSLRLYARWQSRWRKKV DPSAVQGQGPGHRQRRAGRHTASVHHLVYHHHHHHHHHYHFSHGSPRRPGPEPGACDTRLVRAGAPPSPP SPGRGPPDAESVHSIYHADCHIEGPQERARVAHAAATAAASLRLATGLGTMNYPTILPSGVGSGKGSTSP GPKGKWAGGPPGTGGHGPLSLNSPDPYEKIPHVVGEHGLGQAPGHLSGLSVPCPLPSPPAGTLTCELKSC PYCTRALEDPEGELSGSESGDSDGRGVYEFTQDVRHGDRWDPTRPPRATDTPGPGPGSPQRRAQQRAAPG EPGWMGRLWVTFSGKLRRIVDSKYFSRGIMMAILVNTLSMGVEYHEQPEELTNALEISNIVFTSMFALEM LLKLLACGPLGYIRNPYNIFDGIIVVISVWEIVGQADGGLSVLRTFRLLRVLKLVRFLPALRRQLVVLVK TMDNVATFCTLLMLFIFIFSILGMHLFGCKFSLKTDTGDTVPDRKNFDSLLWAIVTVFQILTQEDWNVVL YNGMASTSSWAALYFVALMTFGNYVLFNLLVAILVEGFQAEGDANRSDTDEDKTSVHFEEDFHKLRELQT TELKMCSLAVTPNGHLEGRGSLSPPLIMCTAATPMPTPKSSPFLDAAPSLPDSRRGSSSSGDPPLGDQKP PASLRSSPCAPWGPSGAWSSRRSSWSSLGRAPSLKRRGQCGERESLLSGEGKGSTDDEAEDGRAAPGPRA TPLRRAESLDPRPLRPAALPPTKCRDRDGQVVALPSDFFLRIDSHREDAAELDDDSEDSCCLRLHKVLEP YKPQWCRSREAWALYLFSPQNRFRVSCQKVITHKMFDHVVLVFIFLNCVTIALERPDIDPGSTERVFLSV SNYIFTAIFVAEMMVKVVALGLLSGEHAYLQSSWNLLDGLLVLVSLVDIVVAMASAGGAKILGVLRVLRL LRTLRPLRVISRAPGLKLVVETLISSLRPIGNIVLICCAFFIIFGILGVQLFKGKFYYCEGPDTRNISTK AQCRAAHYRWVRRKYNFDNLGQALMSLFVLSSKDGWVNIMYDGLDAVGVDQQPVQNHNPWMLLYFISFLL IVSFFVLNMFVGVVVENFHKCRQHQEAEEARRREEKRLRRLERRRRSTFPSPEAQRRPYYADYSPTRRSI HSLCTSHYLDLFITFIICVNVITMSMEHYNQPKSLDEALKYCNYVFTIVFVFEAALKLVAFGFRRFFKDR WNQLDLAIVLLSLMGITLEEIEMSAALPINPTIIRIMRVLRIARVLKLLKMATGMRALLDTVVQALPQVG NLGLLFMLLFFIYAALGVELFGRLECSEDNPCEGLSRHATFSNFGMAFLTLFRVSTGDNWNGIMKDTLRE CSREDKHCLSYLPALSPVYFVTFVLVAQFVLVNVVVAVLMKHLEESNKEAREDAELDAEIELEMAQGPGS ARRVDADRPPLPQESPGARDAPNLVARKVSVSRMLSLPNDSYMFRPVVPASAPHPRPLQEVEMETYGAGT PLGSVASVHSPPAESCASLQIPLAVSSPARSGEPLHALSPRGTARSPSLSRLLCRQEAVHTDSLEGKIDS PRDTLDPAEPGEKTPVRPVTQGGSLQSPPRSPRPASVRTRKHTFGQRCVSSRPAAPGGEEAEASDPADEE VSHITSSACPWQPTAEPHGPEASPVAGGERDLRRLYSVDAQGFLDKPGRADEQWRPSAELGSGEPGEAKA WGPEAEPALGARRKKKMSPPCISVEPPAEDEGSARPSAAEGGSTTLRRRTPSCEATPHRDSLEPTEGSGA GGDPAAKGERWGQASCRAEHLTVPSFAFEPLDLGVPSGDPFLDGSHSVTPESRASSSGAIVPLEPPESEP PMPVGDPPEKRRGLYLTVPQCPLEKPGSPSATPAPGGGADDPV TRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
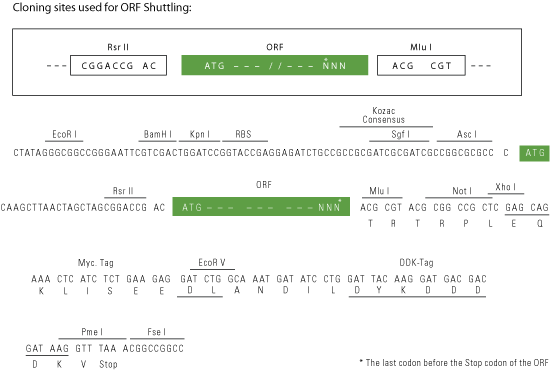
RsrII-MluI
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_021098 |
| ORF Size | 7059 bp |
| OTI Disclaimer | Due to the inherent nature of this plasmid, standard methods to replicate additional amounts of DNA in E. coli are highly likely to result in mutations and/or rearrangements. Therefore, OriGene does not guarantee the capability to replicate this plasmid DNA. Additional amounts of DNA can be purchased from OriGene with batch-specific, full-sequence verification at a reduced cost. Please contact our customer care team at custsupport@origene.com or by calling 301.340.3188 option 3 for pricing and delivery. The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Reference Data | |
| RefSeq | NM_021098.1, NM_021098.2, NP_066921.2 |
| RefSeq Size | 8097 |
| RefSeq ORF | 7062 |
| Locus ID | 8912 |
| Protein Families | Druggable Genome, Ion Channels: Calcium, Transmembrane |
| Protein Pathways | Calcium signaling pathway, MAPK signaling pathway |
| MW | 259 kDa |
| Gene Summary | This gene encodes a T-type member of the alpha-1 subunit family, a protein in the voltage-dependent calcium channel complex. Calcium channels mediate the influx of calcium ions into the cell upon membrane polarization and consist of a complex of alpha-1, alpha-2/delta, beta, and gamma subunits in a 1:1:1:1 ratio. The alpha-1 subunit has 24 transmembrane segments and forms the pore through which ions pass into the cell. There are multiple isoforms of each of the proteins in the complex, either encoded by different genes or the result of alternative splicing of transcripts. Alternate transcriptional splice variants, encoding different isoforms, have been characterized for the gene described here. Studies suggest certain mutations in this gene lead to childhood absence epilepsy (CAE). [provided by RefSeq, Jul 2008] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| SC304910 | CACNA1H (untagged)-Human calcium channel, voltage-dependent, T type, alpha 1H subunit (CACNA1H), transcript variant 1 |
USD 4,780.00 |
|
| RG212772 | CACNA1H (GFP-tagged) - Human calcium channel, voltage-dependent, T type, alpha 1H subunit (CACNA1H), transcript variant 1 |
USD 3,100.00 |
|
| RC212772L1 | Lenti ORF clone of Human calcium channel, voltage-dependent, T type, alpha 1H subunit (CACNA1H), transcript variant 1, Myc-DDK-tagged |
USD 3,732.00 |
{0} Product Review(s)
Be the first one to submit a review

