


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
CACNA1A (NM_023035) Human Tagged ORF Clone
CAT#: RC214990
- TrueORF®
CACNA1A (Myc-DDK-tagged)-Human calcium channel, voltage-dependent, P/Q type, alpha 1A subunit (CACNA1A), transcript variant 2
"NM_023035" in other vectors (2)
Product Images

Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | CACNA1A |
| Synonyms | APCA; BI; CACNL1A4; CAV2.1; DEE42; EA2; EIEE42; FHM; HPCA; MHP; MHP1; SCA6 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC214990 representing NM_023035.
Blue=ORF Red=Cloning site Green=Tag(s) GCTCGTTTAGTGAACCGTCAGAATTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTG GATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCC ATGGCCCGCTTCGGAGACGAGATGCCGGCCCGCTACGGGGGAGGAGGCTCCGGGGCAGCCGCCGGGGTG GTCGTGGGCAGCGGAGGCGGGCGAGGAGCCGGGGGCAGCCGGCAGGGCGGGCAGCCCGGGGCGCAAAGG ATGTACAAGCAGTCAATGGCGCAGAGAGCGCGGACCATGGCACTCTACAACCCCATCCCCGTCCGACAG AACTGCCTCACGGTTAACCGGTCTCTCTTCCTCTTCAGCGAAGACAACGTGGTGAGAAAATACGCCAAA AAGATCACCGAATGGCCTCCCTTTGAATATATGATTTTAGCCACCATCATAGCGAATTGCATCGTCCTC GCACTGGAGCAGCATCTGCCTGATGATGACAAGACCCCGATGTCTGAACGGCTGGATGACACAGAACCA TACTTCATTGGAATTTTTTGTTTCGAGGCTGGAATTAAAATCATTGCCCTTGGGTTTGCCTTCCACAAA GGCTCCTACTTGAGGAATGGCTGGAATGTCATGGACTTTGTGGTGGTGCTAACGGGCATCTTGGCGACA GTTGGGACGGAGTTTGACCTACGGACGCTGAGGGCAGTTCGAGTGCTGCGGCCGCTCAAGCTGGTGTCT GGAATCCCAAGTTTACAAGTCGTCCTGAAGTCGATCATGAAGGCGATGATCCCTTTGCTGCAGATCGGC CTCCTCCTATTTTTTGCAATCCTTATTTTTGCAATCATAGGGTTAGAATTTTATATGGGAAAATTTCAT ACCACCTGCTTTGAAGAGGGGACAGATGACATTCAGGGTGAGTCTCCGGCTCCATGTGGGACAGAAGAG CCCGCCCGCACCTGCCCCAATGGGACCAAATGTCAGCCCTACTGGGAAGGGCCCAACAACGGGATCACT CAGTTCGACAACATCCTGTTTGCAGTGCTGACTGTTTTCCAGTGCATAACCATGGAAGGGTGGACTGAT CTCCTCTACAATAGCAACGATGCCTCAGGGAACACTTGGAACTGGTTGTACTTCATCCCCCTCATCATC ATCGGCTCCTTTTTTATGCTGAACCTTGTGCTGGGTGTGCTGTCAGGGGAGTTTGCCAAAGAAAGGGAA CGGGTGGAGAACCGGCGGGCTTTTCTGAAGCTGAGGCGGCAACAACAGATTGAACGTGAGCTCAATGGG TACATGGAGTGGATCTCAAAAGCAGAAGAGGTGATCCTCGCCGAGGATGAAACTGACGGGGAGCAGAGG CATCCCTTTGATGGAGCTCTGCGGAGAACCACCATAAAGAAAAGCAAGACAGATTTGCTCAACCCCGAA GAGGCTGAGGATCAGCTGGCTGATATAGCCTCTGTGGGTTCTCCCTTCGCCCGAGCCAGCATTAAAAGT GCCAAGCTGGAGAACTCGACCTTTTTTCACAAAAAGGAGAGGAGGATGCGTTTCTACATCCGCCGCATG GTCAAAACTCAGGCCTTCTACTGGACTGTACTCAGTTTGGTAGCTCTCAACACGCTGTGTGTTGCTATT GTTCACTACAACCAGCCCGAGTGGCTCTCCGACTTCCTTTACTATGCAGAATTCATTTTCTTAGGACTC TTTATGTCCGAAATGTTTATAAAAATGTACGGGCTTGGGACGCGGCCTTACTTCCACTCTTCCTTCAAC TGCTTTGACTGTGGGGTTATCATTGGGAGCATCTTCGAGGTCATCTGGGCTGTCATAAAACCTGGCACA TCCTTTGGAATCAGCGTGTTACGAGCCCTCAGGTTATTGCGTATTTTCAAAGTCACAAAGTACTGGGCA TCTCTCAGAAACCTGGTCGTCTCTCTCCTCAACTCCATGAAGTCCATCATCAGCCTGTTGTTTCTCCTT TTCCTGTTCATTGTCGTCTTCGCCCTTTTGGGAATGCAACTCTTCGGCGGCCAGTTTAATTTCGATGAA GGGACTCCTCCCACCAACTTCGATACTTTTCCAGCAGCAATAATGACGGTGTTTCAGATCCTGACGGGC GAAGACTGGAACGAGGTCATGTACGACGGGATCAAGTCTCAGGGGGGCGTGCAGGGCGGCATGGTGTTC TCCATCTATTTCATTGTACTGACGCTCTTTGGGAACTACACCCTCCTGAATGTGTTCTTGGCCATCGCT GTGGACAATCTGGCCAACGCCCAGGAGCTCACCAAGGTGGAGGCGGACGAGCAAGAGGAAGAAGAAGCA GCGAACCAGAAACTTGCCCTACAGAAAGCCAAGGAGGTGGCAGAAGTGAGTCCTCTGTCCGCGGCCAAC ATGTCTATAGCTGTGAAAGAGCAACAGAAGAATCAAAAGCCAGCCAAGTCCGTGTGGGAGCAGCGGACC AGTGAGATGCGAAAGCAGAACTTGCTGGCCAGCCGGGAGGCCCTGTATAACGAAATGGACCCGGACGAG CGCTGGAAGGCTGCCTACACGCGGCACCTGCGGCCAGACATGAAGACGCACTTGGACCGGCCGCTGGTG GTGGACCCGCAGGAGAACCGCAACAACAACACCAACAAGAGCCGGGCGGCCGAGCCCACCGTGGACCAG CGCCTCGGCCAGCAGCGCGCCGAGGACTTCCTCAGGAAACAGGCCCGCTACCACGATCGGGCCCGGGAC CCCAGCGGCTCGGCGGGCCTGGACGCACGGAGGCCCTGGGCGGGAAGCCAGGAGGCCGAGCTGAGCCGG GAGGGACCCTACGGCCGCGAGTCGGACCACCACGCCCGGGAGGGCAGCCTGGAGCAACCCGGGTTCTGG GAGGGCGAGGCCGAGCGAGGCAAGGCCGGGGACCCCCACCGGAGGCACGTGCACCGGCAGGGGGGCAGC AGGGAGAGCCGCAGCGGGTCCCCGCGCACGGGCGCGGACGGGGAGCATCGACGTCATCGCGCGCACCGC AGGCCCGGGGAGGAGGGTCCGGAGGACAAGGCGGAGCGGAGGGCGCGGCACCGCGAGGGCAGCCGGCCG GCCCGGGGCGGCGAGGGCGAGGGCGAGGGCCCCGACGGGGGCGAGCGCAGGAGAAGGCACCGGCATGGC GCTCCAGCCACGTACGAGGGGGACGCGCGGAGGGAGGACAAGGAGCGGAGGCATCGGAGGAGGAAAGAG AACCAGGGCTCCGGGGTCCCTGTGTCGGGCCCCAACCTGTCAACCACCCGGCCAATCCAGCAGGACCTG GGCCGCCAAGACCCACCCCTGGCAGAGGATATTGACAACATGAAGAACAACAAGCTGGCCACCGCGGAG TCGGCCGCTCCCCACGGCAGCCTTGGCCACGCCGGCCTGCCCCAGAGCCCAGCCAAGATGGGAAACAGC ACCGACCCCGGCCCCATGCTGGCCATCCCTGCCATGGCCACCAACCCCCAGAACGCCGCCAGCCGCCGG ACGCCCAACAACCCGGGGAACCCATCCAATCCCGGCCCCCCCAAGACCCCCGAGAATAGCCTTATCGTC ACCAACCCCAGCGGCACCCAGACCAATTCAGCTAAGACTGCCAGGAAACCCGACCACACCACAGTGGAC ATCCCCCCAGCCTGCCCACCCCCCCTCAACCACACCGTCGTACAAGTGAACAAAAACGCCAACCCAGAC CCACTGCCAAAAAAAGAGGAAGAGAAGAAGGAGGAGGAGGAAGACGACCGTGGGGAAGACGGCCCTAAG CCAATGCCTCCCTATAGCTCCATGTTCATCCTGTCCACGACCAACCCCCTTCGCCGCCTGTGCCATTAC ATCCTGAACCTGCGCTACTTTGAGATGTGCATCCTCATGGTCATTGCCATGAGCAGCATCGCCCTGGCC GCCGAGGACCCTGTGCAGCCCAACGCACCTCGGAACAACGTGCTGCGATACTTTGACTACGTTTTTACA GGCGTCTTTACCTTTGAGATGGTGATCAAGATGATTGACCTGGGGCTCGTCCTGCATCAGGGTGCCTAC TTCCGTGACCTCTGGAATATTCTCGACTTCATAGTGGTCAGTGGGGCCCTGGTAGCCTTTGCCTTCACT GGCAATAGCAAAGGAAAAGACATCAACACGATTAAATCCCTCCGAGTCCTCCGGGTGCTACGACCTCTT AAAACCATCAAGCGGCTGCCAAAGCTCAAGGCTGTGTTTGACTGTGTGGTGAACTCACTTAAAAACGTC TTCAACATCCTCATCGTCTACATGCTATTCATGTTCATCTTCGCCGTGGTGGCTGTGCAGCTCTTCAAG GGGAAATTCTTCCACTGCACTGACGAGTCCAAAGAGTTTGAGAAAGATTGTCGAGGCAAATACCTCCTC TACGAGAAGAATGAGGTGAAGGCGCGAGACCGGGAGTGGAAGAAGTATGAATTCCATTACGACAATGTG CTGTGGGCTCTGCTGACCCTCTTCACCGTGTCCACGGGAGAAGGCTGGCCACAGGTCCTCAAGCATTCG GTGGACGCCACCTTTGAGAACCAGGGCCCCAGCCCCGGGTACCGCATGGAGATGTCCATTTTCTACGTC GTCTACTTTGTGGTGTTCCCCTTCTTCTTTGTCAATATCTTTGTGGCCTTGATCATCATCACCTTCCAG GAGCAAGGGGACAAGATGATGGAGGAATACAGCCTGGAGAAAAATGAGAGGGCCTGCATTGATTTCGCC ATCAGCGCCAAGCCGCTGACCCGACACATGCCGCAGAACAAGCAGAGCTTCCAGTACCGCATGTGGCAG TTCGTGGTGTCTCCGCCTTTCGAGTACACGATCATGGCCATGATCGCCCTCAACACCATCGTGCTTATG ATGAAGTTCTATGGGGCTTCTGTTGCTTATGAAAATGCCCTGCGGGTGTTCAACATCGTCTTCACCTCC CTCTTCTCTCTGGAATGTGTGCTGAAAGTCATGGCTTTTGGGATTCTGAATTATTTCCGCGATGCCTGG AACATCTTCGACTTTGTGACTGTTCTGGGCAGCATCACCGATATCCTCGTGACTGAGTTTGGGAATCCG AATAACTTCATCAACCTGAGCTTTCTCCGCCTCTTCCGAGCTGCCCGGCTCATCAAACTTCTCCGTCAG GGTTACACCATCCGCATTCTTCTCTGGACCTTTGTGCAGTCCTTCAAGGCCCTGCCTTATGTCTGTCTG CTGATCGCCATGCTCTTCTTCATCTATGCCATCATTGGGATGCAGGTGTTTGGTAACATTGGCATCGAC GTGGAGGACGAGGACAGTGATGAAGATGAGTTCCAAATCACTGAGCACAATAACTTCCGGACCTTCTTC CAGGCCCTCATGCTTCTCTTCCGGAGTGCCACCGGGGAAGCTTGGCACAACATCATGCTTTCCTGCCTC AGCGGGAAACCGTGTGATAAGAACTCTGGCATCCTGACTCGAGAGTGTGGCAATGAATTTGCTTATTTT TACTTTGTTTCCTTCATCTTCCTCTGCTCGTTTCTGATGCTGAATCTCTTTGTCGCCGTCATCATGGAC AACTTTGAGTACCTCACCCGAGACTCCTCCATCCTGGGCCCCCACCACCTGGATGAGTACGTGCGTGTC TGGGCCGAGTATGACCCCGCAGCTTGGGGCCGCATGCCTTACCTGGACATGTATCAGATGCTGAGACAC ATGTCTCCGCCCCTGGGTCTGGGGAAGAAGTGTCCGGCCAGAGTGGCTTACAAGCGGCTTCTGCGGATG GACCTGCCCGTCGCAGATGACAACACCGTCCACTTCAATTCCACCCTCATGGCTCTGATCCGCACAGCC CTGGACATCAAGATTGCCAAGGGAGGAGCCGACAAACAGCAGATGGACGCTGAGCTGCGGAAGGAGATG ATGGCGATTTGGCCCAATCTGTCCCAGAAGACGCTAGACCTGCTGGTCACACCTCACAAGTCCACGGAC CTCACCGTGGGGAAGATCTACGCAGCCATGATGATCATGGAGTACTACCGGCAGAGCAAGGCCAAGAAG CTGCAGGCCATGCGCGAGGAGCAGGACCGGACACCCCTCATGTTCCAGCGCATGGAGCCCCCGTCCCCA ACGCAGGAAGGGGGACCTGGCCAGAACGCCCTCCCCTCCACCCAGCTGGACCCAGGAGGAGCCCTGATG GCTCACGAAAGCGGCCTCAAGGAGAGCCCGTCCTGGGTGACCCAGCGTGCCCAGGAGATGTTCCAGAAG ACGGGCACATGGAGTCCGGAACAAGGCCCCCCTACCGACATGCCCAACAGCCAGCCTAACTCTCAGTCC GTGGAGATGCGAGAGATGGGCAGAGATGGCTACTCCGACAGCGAGCACTACCTCCCCATGGAAGGCCAG GGCCGGGCTGCCTCCATGCCCCGCCTCCCTGCAGAGAACCAGAGGAGAAGGGGCCGGCCACGTGGGAAT AACCTCAGTACCATCTCAGACACCAGCCCCATGAAGCGTTCAGCCTCCGTGCTGGGCCCCAAGGCCCGA CGCCTGGACGATTACTCGCTGGAGCGGGTCCCGCCCGAGGAGAACCAGCGGCACCACCAGCGGCGCCGC GACCGCAGCCACCGCGCCTCTGAGCGCTCCCTGGGCCGCTACACCGATGTGGACACAGGCTTGGGGACA GACCTGAGCATGACCACCCAATCCGGGGACCTGCCGTCGAAGGAGCGGGACCAGGAGCGGGGCCGGCCC AAGGATCGGAAGCATCGACAGCACCACCACCACCACCACCACCACCACCATCCCCCGCCCCCCGACAAG GACCGCTATGCCCAGGAACGGCCGGACCACGGCCGGGCACGGGCTCGGGACCAGCGCTGGTCCCGCTCG CCCAGCGAGGGCCGAGAGCACATGGCGCACCGGCAGGGCAGTAGTTCCGTAAGTGGAAGCCCAGCCCCC TCAACATCTGGTACCAGCACTCCGCGGCGGGGCCGCCGCCAGCTCCCCCAGACCCCCTCCACCCCCCGG CCACACGTGTCCTATTCCCCTGTGATCCGTAAGGCCGGCGGCTCGGGGCCCCCGCAGCAGCAGCAGCAG CAGCAGCAGCAGCAGCAGCAGCAGGCGGTGGCCAGGCCGGGCCGGGCGGCCACCAGCGGCCCTCGGAGG TACCCAGGCCCCACGGCCGAGCCTCTGGCCGGAGATCGGCCGCCCACGGGGGGCCACAGCAGCGGCCGC TCGCCCAGGATGGAGAGGCGGGTCCCAGGCCCGGCCCGGAGCGAGTCCCCCAGGGCCTGTCGACACGGC GGGGCCCGGTGGCCGGCATCTGGCCCGCACGTGTCCGAGGGGCCCCCGGGTCCCCGGCACCATGGCTAC TACCGGGGCTCCGACTACGACGAGGCCGATGGCCCGGGCAGCGGGGGCGGCGAGGAGGCCATGGCCGGG GCCTACGACGCGCCACCCCCCGTACGACACGCGTCCTCGGGCGCCACCGGGCGCTCGCCCAGGACTCCC CGGGCCTCGGGCCCGGCCTGCGCCTCGCCTTCTCGGCACGGCCGGCGACTCCCCAACGGCTACTACCCG GCGCACGGACTGGCCAGGCCCCGCGGGCCGGGCTCCAGGAAGGGCCTGCACGAACCCTACAGCGAGAGT GACGATGATTGGTGC AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGAT ATCCTGGATTACAAGGATGACGACGATAAGGTTTAA >Peptide sequence encoded by RC214990
Blue=ORF Red=Cloning site Green=Tag(s) MARFGDEMPARYGGGGSGAAAGVVVGSGGGRGAGGSRQGGQPGAQRMYKQSMAQRARTMALYNPIPVRQ NCLTVNRSLFLFSEDNVVRKYAKKITEWPPFEYMILATIIANCIVLALEQHLPDDDKTPMSERLDDTEP YFIGIFCFEAGIKIIALGFAFHKGSYLRNGWNVMDFVVVLTGILATVGTEFDLRTLRAVRVLRPLKLVS GIPSLQVVLKSIMKAMIPLLQIGLLLFFAILIFAIIGLEFYMGKFHTTCFEEGTDDIQGESPAPCGTEE PARTCPNGTKCQPYWEGPNNGITQFDNILFAVLTVFQCITMEGWTDLLYNSNDASGNTWNWLYFIPLII IGSFFMLNLVLGVLSGEFAKERERVENRRAFLKLRRQQQIERELNGYMEWISKAEEVILAEDETDGEQR HPFDGALRRTTIKKSKTDLLNPEEAEDQLADIASVGSPFARASIKSAKLENSTFFHKKERRMRFYIRRM VKTQAFYWTVLSLVALNTLCVAIVHYNQPEWLSDFLYYAEFIFLGLFMSEMFIKMYGLGTRPYFHSSFN CFDCGVIIGSIFEVIWAVIKPGTSFGISVLRALRLLRIFKVTKYWASLRNLVVSLLNSMKSIISLLFLL FLFIVVFALLGMQLFGGQFNFDEGTPPTNFDTFPAAIMTVFQILTGEDWNEVMYDGIKSQGGVQGGMVF SIYFIVLTLFGNYTLLNVFLAIAVDNLANAQELTKVEADEQEEEEAANQKLALQKAKEVAEVSPLSAAN MSIAVKEQQKNQKPAKSVWEQRTSEMRKQNLLASREALYNEMDPDERWKAAYTRHLRPDMKTHLDRPLV VDPQENRNNNTNKSRAAEPTVDQRLGQQRAEDFLRKQARYHDRARDPSGSAGLDARRPWAGSQEAELSR EGPYGRESDHHAREGSLEQPGFWEGEAERGKAGDPHRRHVHRQGGSRESRSGSPRTGADGEHRRHRAHR RPGEEGPEDKAERRARHREGSRPARGGEGEGEGPDGGERRRRHRHGAPATYEGDARREDKERRHRRRKE NQGSGVPVSGPNLSTTRPIQQDLGRQDPPLAEDIDNMKNNKLATAESAAPHGSLGHAGLPQSPAKMGNS TDPGPMLAIPAMATNPQNAASRRTPNNPGNPSNPGPPKTPENSLIVTNPSGTQTNSAKTARKPDHTTVD IPPACPPPLNHTVVQVNKNANPDPLPKKEEEKKEEEEDDRGEDGPKPMPPYSSMFILSTTNPLRRLCHY ILNLRYFEMCILMVIAMSSIALAAEDPVQPNAPRNNVLRYFDYVFTGVFTFEMVIKMIDLGLVLHQGAY FRDLWNILDFIVVSGALVAFAFTGNSKGKDINTIKSLRVLRVLRPLKTIKRLPKLKAVFDCVVNSLKNV FNILIVYMLFMFIFAVVAVQLFKGKFFHCTDESKEFEKDCRGKYLLYEKNEVKARDREWKKYEFHYDNV LWALLTLFTVSTGEGWPQVLKHSVDATFENQGPSPGYRMEMSIFYVVYFVVFPFFFVNIFVALIIITFQ EQGDKMMEEYSLEKNERACIDFAISAKPLTRHMPQNKQSFQYRMWQFVVSPPFEYTIMAMIALNTIVLM MKFYGASVAYENALRVFNIVFTSLFSLECVLKVMAFGILNYFRDAWNIFDFVTVLGSITDILVTEFGNP NNFINLSFLRLFRAARLIKLLRQGYTIRILLWTFVQSFKALPYVCLLIAMLFFIYAIIGMQVFGNIGID VEDEDSDEDEFQITEHNNFRTFFQALMLLFRSATGEAWHNIMLSCLSGKPCDKNSGILTRECGNEFAYF YFVSFIFLCSFLMLNLFVAVIMDNFEYLTRDSSILGPHHLDEYVRVWAEYDPAAWGRMPYLDMYQMLRH MSPPLGLGKKCPARVAYKRLLRMDLPVADDNTVHFNSTLMALIRTALDIKIAKGGADKQQMDAELRKEM MAIWPNLSQKTLDLLVTPHKSTDLTVGKIYAAMMIMEYYRQSKAKKLQAMREEQDRTPLMFQRMEPPSP TQEGGPGQNALPSTQLDPGGALMAHESGLKESPSWVTQRAQEMFQKTGTWSPEQGPPTDMPNSQPNSQS VEMREMGRDGYSDSEHYLPMEGQGRAASMPRLPAENQRRRGRPRGNNLSTISDTSPMKRSASVLGPKAR RLDDYSLERVPPEENQRHHQRRRDRSHRASERSLGRYTDVDTGLGTDLSMTTQSGDLPSKERDQERGRP KDRKHRQHHHHHHHHHHPPPPDKDRYAQERPDHGRARARDQRWSRSPSEGREHMAHRQGSSSVSGSPAP STSGTSTPRRGRRQLPQTPSTPRPHVSYSPVIRKAGGSGPPQQQQQQQQQQQQQAVARPGRAATSGPRR YPGPTAEPLAGDRPPTGGHSSGRSPRMERRVPGPARSESPRACRHGGARWPASGPHVSEGPPGPRHHGY YRGSDYDEADGPGSGGGEEAMAGAYDAPPPVRHASSGATGRSPRTPRASGPACASPSRHGRRLPNGYYP AHGLARPRGPGSRKGLHEPYSESDDDWC SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
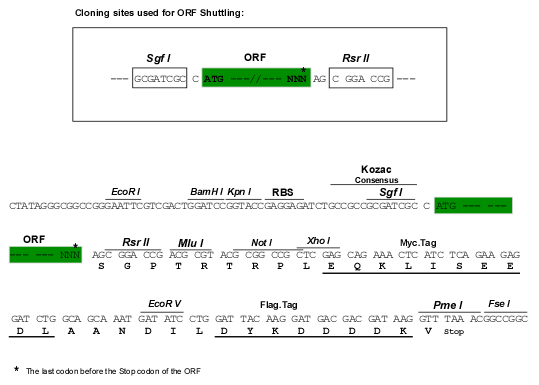
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_023035 |
| ORF Size | 7536 bp |
| OTI Disclaimer | Due to the inherent nature of this plasmid, standard methods to replicate additional amounts of DNA in E. coli are highly likely to result in mutations and/or rearrangements. Therefore, OriGene does not guarantee the capability to replicate this plasmid DNA. Additional amounts of DNA can be purchased from OriGene with batch-specific, full-sequence verification at a reduced cost. Please contact our customer care team at custsupport@origene.com or by calling 301.340.3188 option 3 for pricing and delivery. The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_023035.3 |
| RefSeq Size | 8646 bp |
| RefSeq ORF | 7539 bp |
| Locus ID | 773 |
| UniProt ID | O00555 |
| Cytogenetics | 19p13.13 |
| Protein Families | Druggable Genome, Ion Channels: Calcium, Transmembrane |
| Protein Pathways | Calcium signaling pathway, Long-term depression, MAPK signaling pathway, Taste transduction, Type II diabetes mellitus |
| MW | 283.1 kDa |
| Gene Summary | Voltage-dependent calcium channels mediate the entry of calcium ions into excitable cells, and are also involved in a variety of calcium-dependent processes, including muscle contraction, hormone or neurotransmitter release, and gene expression. Calcium channels are multisubunit complexes composed of alpha-1, beta, alpha-2/delta, and gamma subunits. The channel activity is directed by the pore-forming alpha-1 subunit, whereas, the others act as auxiliary subunits regulating this activity. The distinctive properties of the calcium channel types are related primarily to the expression of a variety of alpha-1 isoforms, alpha-1A, B, C, D, E, and S. This gene encodes the alpha-1A subunit, which is predominantly expressed in neuronal tissue. Mutations in this gene are associated with 2 neurologic disorders, familial hemiplegic migraine and episodic ataxia 2. This gene also exhibits polymorphic variation due to (CAG)n-repeats. Multiple transcript variants encoding different isoforms have been found for this gene. In one set of transcript variants, the (CAG)n-repeats occur in the 3' UTR, and are not associated with any disease. But in another set of variants, an insertion extends the coding region to include the (CAG)n-repeats which encode a polyglutamine tract. Expansion of the (CAG)n-repeats from the normal 4-18 to 21-33 in the coding region is associated with spinocerebellar ataxia 6. [provided by RefSeq, Jul 2016] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RG214990 | CACNA1A (GFP-tagged) - Human calcium channel, voltage-dependent, P/Q type, alpha 1A subunit (CACNA1A), transcript variant 2 |
USD 3,310.00 |
|
| RC214990L1 | Lenti ORF clone of Human calcium channel, voltage-dependent, P/Q type, alpha 1A subunit (CACNA1A), transcript variant 2, Myc-DDK-tagged |
USD 3,972.00 |
{0} Product Review(s)
Be the first one to submit a review

