


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Sialoadhesin (SIGLEC1) (NM_023068) Human Tagged ORF Clone
CAT#: RC224969

SIGLEC1 (Myc-DDK-tagged)-Human sialic acid binding Ig-like lectin 1, sialoadhesin (SIGLEC1)
"NM_023068" in other vectors (3)
Product Images
 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC224969 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
. The protein was produced from HEK293T cells transfected with SIGLEC1 cDNA clone (Cat# RC224969) using MegaTran 2.0 (Cat# TT210002).")
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | SIGLEC1 |
| Synonyms | CD169; SIGLEC-1; SN |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC224969 representing NM_023068
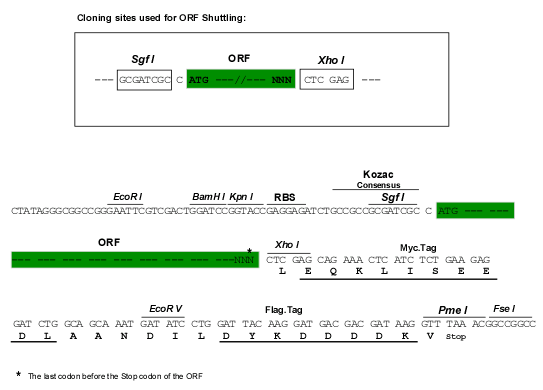
Red=Cloning site Blue=ORF Green=Tags(s) CTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGGCTTCTTGCCCAAGCTTCTCCTCCTGGCCTCATTCTTCCCAGCAGGCCAGGCCTCATGGGGCGTCT CCAGTCCCCAGGACGTGCAGGGTGTGAAGGGGTCTTGCCTGCTTATCCCCTGCATCTTCAGCTTCCCTGC CGACGTGGAGGTGCCCGACGGCATCACGGCCATCTGGTACTACGACTACTCGGGCCAGCGGCAGGTGGTG AGCCACTCGGCGGACCCCAAGCTGGTGGAGGCCCGCTTCCGCGGCCGCACCGAGTTCATGGGGAACCCCG AGCACAGGGTGTGCAACCTGCTGCTGAAGGACCTGCAGCCCGAGGACTCTGGTTCCTACAACTTCCGCTT CGAGATCAGTGAGGTCAACCGCTGGTCAGATGTGAAAGGCACCTTGGTCACAGTAACAGAGGAGCCCAGG GTGCCCACCATTGCCTCCCCGGTGGAGCTTCTCGAGGGCACAGAGGTGGACTTCAACTGCTCCACTCCCT ACGTATGCCTGCAGGAGCAGGTCAGACTGCAGTGGCAAGGCCAGGACCCTGCTCGCTCTGTCACCTTCAA CAGCCAGAAGTTTGAGCCCACCGGCGTCGGCCACCTGGAGACCCTCCACATGGCCATGTCCTGGCAGGAC CACGGCCGGATCCTGCGCTGCCAGCTCTCCATGGCCAATCACAGGGCTCAGAGCGAGATTCACCTCCAAG TGAAGTATGCCCCCAGGGGTGTGAAGATCCTCCTCAGCCCCTCGGGGAGGAACATCCTTCCAGGTGAGCT GGTCACACTCACCTGCCAGGTGAACAGCAGCTACCCTGCAGTCAGTTCCATTAAGTGGCTCAAGGATGGG GTACGCCTCCAAACCAAGACTGGTGTGCTGCACCTGCCCCAGGCAGCCTGGAGCGATGCTGGCGTCTACA CCTGCCAAGCTGAGAACGGCGTGGGCTCTTTGGTCTCACCCCCCATCAGCCTCCACATCTTCATGGCTGA GGTCCAGGTGAGCCCAGCAGGTCCCATCCTGGAGAACCAGACAGTGACACTAGTCTGCAACACACCCAAC GAGGCACCCAGTGATCTCCGCTACAGCTGGTACAAGAACCATGTCCTGCTGGAGGATGCCCACTCCCATA CCCTCCGGCTGCACTTGGCCACTAGGGCTGATACTGGCTTCTACTTCTGTGAGGTGCAGAACGTCCATGG CAGCGAGCGCTCGGGCCCTGTCAGCGTGGTAGTCAACCACCCGCCTCTCACCCCAGTCCTGACAGCCTTC CTGGAGACCCAGGCGGGACTTGTGGGCATCCTTCACTGCTCTGTGGTCAGTGAGCCCCTGGCCACACTGG TGCTGTCACATGGGGGTCATATCCTGGCCTCCACCTCCGGGGACAGTGATCACAGCCCACGCTTCAGTGG TACCTCTGGTCCCAACTCCCTGCGCCTGGAGATCCGAGACCTGGAGGAAACTGACAGTGGGGAGTACAAG TGCTCAGCCACCAACTCCCTTGGAAATGCAACCTCYACCCTGGACTTCCATGCCAATGCCGCCCGTCTCC TCATCAGCCCGGCAGCCGAGGTGGTGGAAGGACAGGCAGTGACACTGAGCTGCAGAAGCGGCCTAAGCCC CACACCTGATGCCCGCTTCTCCTGGTACCTGAATGGAGCCCTGCTTCACGAGGGTCCCGGCAGCAGCCTC CTGCTCCCCGCGGCCTCCAGCACTGACGCCGGCTCATACCACTGCCGGGCCCGGGACGGCCACAGTGCCA GTGGCCCCTCTTCGCCAGCTGTTCTCACTGTGCTCTACCCCCCTCGACAACCAACATTCACCACCAGGCT GGACCTTGATGCCGCTGGGGCCGGGGCTGGACGGCGAGGCCTCCTTTTGTGCCGTGTGGACAGCGACCCC CCCGCCAGGCTGCAGCTGCTCCACAAGGACCGTGTTGTGGCCACTTCCCTGCCATCAGGGGGTGGCTGCA GCACCTGTGGGGGCTGTTCCCCACGCATGAAGGTCACCAAAGCCCCCAACTTGCTGCGTGTGGAGATTCA CAACCCTTTGCTGGAAGAGGAGGGCTTGTACCTCTGTGAGGCCAGCAATGCCCTGGGCAACGCCTCCACC TCAGCCACCTTCAATGGCCAGGCCACTGTCCTGGCCATTGCACCATCACACACACTTCAGGAGGGCACAG AAGCCAACTTGACTTGCAACGTGAGCCGGGAAGCTGCTGGCAGCCCTGCTAACTTCTCCTGGTTCCGAAA TGGGGTGCTGTGGGCCCAGGGTCCCCTGGAGACCGTGACACTGCTGCCCGTGGCCAGAACTGATGCTGCC CTTTACGCCTGCCGCATCCTGACTGAGGCTGGTGCCCAGCTCTCCACTCCCGTGCTCCTGAGTGTCCTCT ATCCCCCGGACCGTCCAAAGCTGTCAGCCCTCCTAGACATGGGCCAGGGCCACATGGCTCTGTTCATCTG CACTGTGGACAGCCGCCCCCTGGCCTTGCTGGCCTTGTTCCATGGGGAGCACCTCCTGGCCACCAGCCTG GGTCCCCAGGTCCCATCCCATGGTCGGTTCCAGGCTAAGGCTGAGGCCAACTCCCTGAAGTTAGAGGTCC GAGAACTGGGCCTTGGGGACTCTGGCAGCTACCGCTGTGAGGCCACAAATGTTCTTGGATCATCCAACAC CTCACTCTTCTTCCAGGTCCGAGGAGCCTGGGTCCAGGTGTCACCATCACCTGAGCTCCAAGAGGGCCAG GCTGTGGTCCTGAGCTGCCAGGTACCCACAGGAGTCCCAGAGGGGACCTCATATCGTTGGTATCGGGATG GCCAGCCCCTCCAGGAGTCGACCTCGGCCACGCTCCGCTTTGCAGCCATAACTTTGACACAAGCTGGGGC CTATCATTGCCAAGCCCAGGCCCCAGGCTCAGCCACCACGAGCCTAGCTGTACCCATCAGCCTCCACGTG TCCTATGCCCCACGCCACGTCACACTCACTACCCTGATGGACACAGGCCCTGGACGACTGGGCCTCCTCC TGTGCCGTGTGGACAGTGACCCTCCGGCCCAGCTGCGGCTGCTCCACGGGGATCGCCTTGTGGCCTCCAC CCTACAAGGTGTGGGGGGACCCGAAGGCAGCTCTCCCAGGCTGCATGTGGCTGTGGCCCCCAACACACTG CGTCTGGAGATCCACGGGGCTATGCTGGAGGATGAGGGTGTCTATATCTGTGAGGCCTCCAACACCCTGG GCCAGGCCTCGGCCTCAGCTGACTTCGACGCTCAAGCTGTGAATGTGCAGGTGTGGCCCGGGGCTACCGT GCGGGAGGGGCAGCTGGTGAACCTGACCTGCCTTGTGTGGACCACTCACCCGGCCCAGCTCACCTACACA TGGTACCAGGATGGGCAGCAGCGCCTGGATGCCCACTCCATCCCCCTGCCCAACGTCACAGTCAGGGATG CCACCTCCTACCGCTGCGGTGTGGGCCCCCCTGGTCGGGCACCCCGCCTCTCCAGACCTATCACCTTGGA CGTCCTCTACGCGCCCCGCAACCTGCGCCTGACCTACCTCCTGGAGAGCCATGGCGGGCAGCTGGCCCTG GTACTGTGCACTGTGGACAGCCGCCCGCCCGCCCAGCTGGCCCTCAGCCACGCCGGTCGCCTCTTGGCCT CCTCGACAGCAGCCTCTGTCCCCAACACCCTGCGCCTGGAGCTGCGAGGGCCACAGCCCAGGGATGAGGG TTTCTACAGCTGCTCTGCCCGCAGCCCTCTGGGCCAGGCCAACACGTCCCTGGAGCTGCGGCTGGAGGGT GTGCGGGTGATCCTGGCTCCGGAGGCTGCCGTGCCTGAAGGTGCCCCCATCACAGTGACCTGTGCGGACC CTGCTGCCCACGCACCCACACTCTATACTTGGTACCACAACGGTCGTTGGCTGCAGGAGGGTCCAGCTGC CTCACTCTCATTCCTGGTGGCCACGCGGGCTCATGCAGGCGCCTACTCTTGCCAGGCCCAGGATGCCCAG GGCACCCGCAGCTCCCGTCCTGCTGCCCTGCAAGTCCTCTATGCCCCTCAGGATGCTGTCCTGTCCTCCT TCCGGGACTCCAGGGCCAGATCCATGGCTGTGATACAGTGCACTGTGGACAGTGAGCCACCTGCTGAGCT GGCCCTATCTCATGATGGCAAGGTGCTGGCCACGAGCAGCGGGGTCCACAGCTTGGCATCAGGGACAGGC CATGTCCAGGTGGCCCGAAACGCCCTACGGCTGCAGGTGCAAGATGTGCCTGCAGGTGATGACACCTATG TTTGCACAGCCCAAAACTTGCTGGGCTCAATCAGCACCATCGGGCGGTTGCAGGTAGAAGGTGCACGCGT GGTGGCAGAGCCTGGCCTGGACGTGCCTGAGGGCGCTGCCCTGAACCTCAGCTGCCGCCTCCTGGGTGGC CCTGGGCCTGTGGGCAACTCCACCTTTGCATGGTTCTGGAATGACCGGCGGCTGCACGCGGAGCCTGTGC CCACTCTCGCCTTCACCCACGTGGCTCGTGCTCAAGCTGGGATGTACCACTGCCTGGCTGAGCTCCCCAC TGGGGCTGCTGCCTCTGCTCCAGTCATGCTCCGTGTGCTCTACCCTCCCAAGACGCCCACCATGATGGTC TTCGTGGAGCCTGAGGGTGGCCTCCGGGGCATCCTGGATTGCCGAGTGGACAGCGAGCCGCTCGCCAGCC TGACTCTCCACCTTGGCAGTCGACTGGTGGCCTCCAGTCAGCCCCAGGGTGCTCCTGCAGAGCCACACAT CCATGTCCTGGCTTCCCCCAATGCCCTGAGGGTGGACATCGAGGCGCTGAGGCCCAGCGACCAAGGGGAA TACATCTGTTCTGCCTCAAATGTCCTGGGCTCTGCCTCTACCTCCACCTACTTTGGGGTCAGAGCCCTGC ACCGCCTGCATCAGTTCCAGCAGCTGCTCTGGGTCCTGGGACTGCTGGTGGGCCTCCTGCTCCTGCTGTT GGGCCTGGGGGCCTGCTACACCTGGAGAAGGAGGCGTGTTTGTAAGCAGAGCATGGGCGAGAATTCGGTG GAGATGGCTTTTCAGAAAGAGACCACGCAGCTCATTGATCCTGATGCAGCCACATGTGAGACCTCAACCT GTGCCCCACCCCTGGGC CTCGAGCAGAAACTCATCTCTGAAGAGGATCTGGCAGCAAATGATATCCTGGATTACAAGGATGACGACG ATAAGGTTTAA >RC224969 representing NM_023068
Red=Cloning site Green=Tags(s) MGFLPKLLLLASFFPAGQASWGVSSPQDVQGVKGSCLLIPCIFSFPADVEVPDGITAIWYYDYSGQRQVV SHSADPKLVEARFRGRTEFMGNPEHRVCNLLLKDLQPEDSGSYNFRFEISEVNRWSDVKGTLVTVTEEPR VPTIASPVEL LEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
SgfI-XhoI
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_023068 |
| ORF Size | 5127 bp |
| OTI Disclaimer | Due to the inherent nature of this plasmid, standard methods to replicate additional amounts of DNA in E. coli are highly likely to result in mutations and/or rearrangements. Therefore, OriGene does not guarantee the capability to replicate this plasmid DNA. Additional amounts of DNA can be purchased from OriGene with batch-specific, full-sequence verification at a reduced cost. Please contact our customer care team at custsupport@origene.com or by calling 301.340.3188 option 3 for pricing and delivery. The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified, transfection-ready dried plasmid DNA, and shipped with 2 vector sequencing primers. |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_023068.1, NM_023068.2, NM_023068.3, NP_075556.1 |
| RefSeq Size | 5130 bp |
| RefSeq ORF | 5130 bp |
| Locus ID | 6614 |
| Cytogenetics | 20p13 |
| Protein Families | Transmembrane |
| Protein Pathways | Cell adhesion molecules (CAMs) |
| MW | 180.6 kDa |
| Gene Summary | 'This gene encodes a member of the immunoglobulin superfamily. The encoded protein is a lectin-like adhesion molecule that binds glycoconjugate ligands on cell surfaces in a sialic acid-dependent manner. It is a type I transmembrane protein expressed only by a subpopulation of macrophages and is involved in mediating cell-cell interactions. Alternative splicing produces a transcript variant encoding an isoform that is soluble rather than membrane-bound; however, the full-length nature of this variant has not been determined. [provided by RefSeq, Jul 2008]' |
{kind=link}
Documents
| Product Manuals |
| FAQs |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| SC305076 | SIGLEC1 (untagged)-Human sialic acid binding Ig-like lectin 1, sialoadhesin (SIGLEC1) |
USD 3,460.00 |
|
| RG224969 | SIGLEC1 (GFP-tagged) - Human sialic acid binding Ig-like lectin 1, sialoadhesin (SIGLEC1) |
USD 1,640.00 |
|
| RC224969L3 | Lenti ORF clone of Human sialic acid binding Ig-like lectin 1, sialoadhesin (SIGLEC1), Myc-DDK-tagged |
USD 1,690.00 |
{0} Product Review(s)
Be the first one to submit a review

