


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
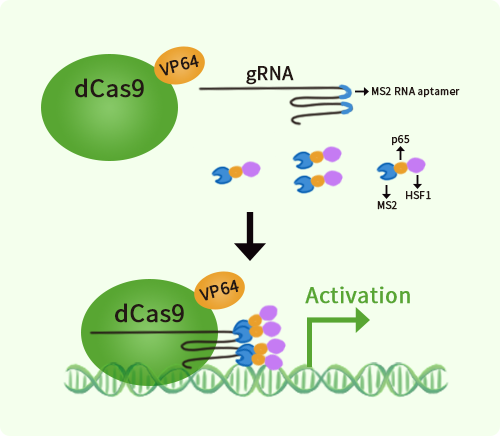
Human CD6 activation kit by CRISPRa
CAT#: GA100650
CD6 CRISPRa kit - CRISPR gene activation of human CD6 molecule
Find the corresponding CRISPRi Inhibitor Kit
USD 1,290.00
2 Weeks*
Product Images
Specifications
| Product Data | |
| Format | 3gRNAs, 1 scramble ctrl and 1 enhancer vector |
| Symbol | CD6 |
| Locus ID | 923 |
| Kit Components | GA100650G1, CD6 gRNA vector 1 in pCas-Guide-GFP-CRISPRa GA100650G2, CD6 gRNA vector 2 in pCas-Guide-GFP-CRISPRa GA100650G3, CD6 gRNA vector 3 in pCas-Guide-GFP-CRISPRa 1 CRISPRa-Enhancer vector, SKU GE100056 1 CRISPRa scramble vector, SKU GE100077 |
| Disclaimer | The kit is designed based on the best knowledge of CRISPa SAM technology. The efficiency of the activation can be affected by many factors, including nucleosome occupancy status, chromatin structure and the gene expression level of the target, etc. |
| Reference Data | |
| RefSeq | NM_001254750, NM_001254751, NM_006725, NR_045638 |
| Synonyms | TP120 |
| Summary | 'This gene encodes a protein found on the outer membrane of T-lymphocytes as well as some other immune cells. The encoded protein contains three scavenger receptor cysteine-rich (SRCR) domains and a binding site for an activated leukocyte cell adhesion molecule. The gene product is important for continuation of T cell activation. This gene may be associated with susceptibility to multiple sclerosis (PMID: 19525953, 21849685). Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Dec 2011]' |
Documents
| Product Manuals |
| FAQs |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| KN410045 | CD6 - KN2.0, Human gene knockout kit via CRISPR, non-homology mediated. |
USD 1,290.00 |
{0} Product Review(s)
Be the first one to submit a review