


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Human PCOLCE activation kit by CRISPRa
CAT#: GA103420
PCOLCE CRISPRa kit - CRISPR gene activation of human procollagen C-endopeptidase enhancer
Find the corresponding CRISPRi Inhibitor Kit
USD 1,290.00
2 Weeks*
Product Images
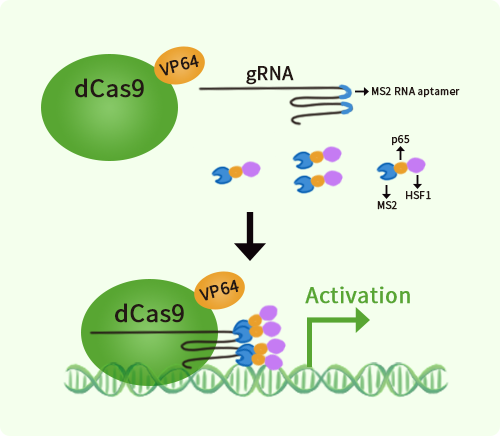
Specifications
| Product Data | |
| Format | 3gRNAs, 1 scramble ctrl and 1 enhancer vector |
| Symbol | PCOLCE |
| Locus ID | 5118 |
| Kit Components | GA103420G1, PCOLCE gRNA vector 1 in pCas-Guide-GFP-CRISPRa GA103420G2, PCOLCE gRNA vector 2 in pCas-Guide-GFP-CRISPRa GA103420G3, PCOLCE gRNA vector 3 in pCas-Guide-GFP-CRISPRa 1 CRISPRa-Enhancer vector, SKU GE100056 1 CRISPRa scramble vector, SKU GE100077 |
| Disclaimer | The kit is designed based on the best knowledge of CRISPa SAM technology. The efficiency of the activation can be affected by many factors, including nucleosome occupancy status, chromatin structure and the gene expression level of the target, etc. |
| Reference Data | |
| RefSeq | NM_002593 |
| Synonyms | PCPE; PCPE-1; PCPE1 |
| Summary | 'Fibrillar collagen types I-III are synthesized as precursor molecules known as procollagens. These precursors contain amino- and carboxyl-terminal peptide extensions known as N- and C-propeptides, respectively, which are cleaved, upon secretion of procollagen from the cell, to yield the mature triple helical, highly structured fibrils. This gene encodes a glycoprotein which binds and drives the enzymatic cleavage of type I procollagen and heightens C-proteinase activity. [provided by RefSeq, Jul 2008]' |
Documents
| Product Manuals |
| FAQs |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| KN400515 | PCOLCE - KN2.0, Human gene knockout kit via CRISPR, non-homology mediated. |
USD 1,290.00 |
{0} Product Review(s)
Be the first one to submit a review