


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Neurofascin (NFASC) (NM_015090) Human Tagged ORF Clone
CAT#: RG214686
- TrueORF®
NFASC (GFP-tagged) - Human neurofascin (NFASC), transcript variant 4
"NM_015090" in other vectors (2)
Product Images
Other products for "NFASC"
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | TurboGFP |
| Symbol | NFASC |
| Synonyms | NEDCPMD; NF; NRCAML |
| Vector | pCMV6-AC-GFP |
| E. coli Selection | Ampicillin (100 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RG214686 representing NM_015090
Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGCCAGGCAGCCACCGCCGCCCTGGGTCCATGCAGCCTTCCTCCTCTGCCTCCTCAGTCTTGGCGGAG CCATCGAAATTCCTATGGATCTGACGCAGCCGCCAACCATCACCAAGCAGTCAGCGAAGGATCACATCGT GGACCCCCGTGATAACATCCTGATTGAGTGTGAAGCAAAAGGGAACCCTGCCCCCAGCTTCCACTGGACA CGAAACAGCAGATTCTTCAACATCGCCAAGGACCCCCGGGTGTCCATGAGGAGGAGGTCTGGGACCCTGG TGATTGACTTCCGCAGTGGCGGGCGGCCGGAGGAATATGAGGGGGAATATCAGTGCTTCGCCCGCAACAA ATTTGGCACGGCCCTGTCCAATAGGATCCGCCTGCAGGTGTCTAAATCTCCTCTGTGGCCCAAGGAAAAC CTAGACCCTGTCGTGGTCCAAGAGGGCGCTCCTTTGACGCTCCAGTGCAACCCCCCGCCTGGACTTCCAT CCCCGGTCATCTTCTGGATGAGCAGCTCCATGGAGCCCATCACCCAAGACAAACGTGTCTCTCAGGGCCA TAACGGAGACCTATACTTCTCCAACGTGATGCTGCAGGACATGCAGACCGACTACAGTTGTAACGCCCGC TTCCACTTCACCCACACCATCCAGCAGAAGAACCCTTTCACCCTCAAGGTCCTCACCAACCACCCTTATA ATGACTCGTCCTTAAGAAACCACCCTGACATGTACAGTGCCCGAGGAGTTGCAGAAAGAACACCAAGCTT CATGTATCCCCAGGGCACCGCGAGCAGCCAGATGGTGCTTCGTGGCATGGACCTCCTGCTGGAATGCATC GCCTCCGGGGTCCCAACACCAGACATCGCATGGTACAAGAAAGGTGGGGACCTCCCATCTGATAAGGCCA AGTTTGAGAACTTTAATAAGGCCCTGCGTATCACAAATGTCTCTGAGGAAGACTCCGGGGAGTATTTCTG CCTGGCCTCCAACAAGATGGGCAGCATCCGGCACACGATCTCGGTGAGAGTAAAGGCTGCTCCCTACTGG CTGGACGAACCCAAGAACCTTATTCTGGCTCCTGGCGAGGATGGGAGACTGGTGTGTCGAGCCAATGGAA ACCCCAAACCCACTGTCCAGTGGATGGTGAATGGGGAACCTTTGCAATCGGCACCACCTAACCCAAACCG TGAGGTGGCCGGAGACACCATCATCTTCCGGGACACCCAGATCAGCAGCAGGGCTGTGTACCAGTGCAAC ACCTCCAACGAGCATGGCTACCTGCTGGCCAACGCCTTTGTCAGTGTGCTGGATGTGCCGCCTCGGATGC TGTCGCCCCGGAACCAGCTCATTCGAGTGATTCTTTACAACCGGACGCGGCTGGACTGCCCTTTCTTTGG GTCTCCCATCCCCACACTGCGATGGTTTAAGAATGGGCAAGGAAGCAACCTGGATGGTGGCAACTACCAT GTTTATGAGAACGGCAGTCTGGAAATTAAGATGATCCGCAAAGAGGACCAGGGCATCTACACCTGTGTCG CCACCAACATCCTGGGCAAAGCTGAAAACCAAGTCCGCCTGGAGGTCAAAGACCCCACCAGGATCTACCG GATGCCCGAGGACCAGGTGGCCAGAAGGGGCACCACGGTGCAGCTGGAGTGTCGGGTGAAGCACGACCCC TCCCTGAAACTCACCGTCTCCTGGCTGAAGGATGACGAGCCGCTCTATATTGGAAACAGGATGAAGAAGG AAGACGACTCCCTGACCATCTTTGGGGTGGCAGAGCGGGACCAGGGCAGTTACACGTGTGTCGCCAGCAC CGAGCTAGACCAAGACCTGGCCAAGGCCTACCTCACCGTGCTAGGACGGCCAGACCGGCCCCGGGACCTG GAGCTGACCGACCTGGCCGAGAGGAGCGTGCGGCTGACCTGGATCCCCGGGGATGCTAACAACAGCCCCA TCACAGACTACGTCGTCCAGTTTGAAGAAGACCAGTTCCAACCTGGGGTCTGGCATGACCATTCCAAGTA CCCCGGCAGCGTTAACTCAGCCGTCCTCCGGCTGTCCCCGTATGTCAACTACCAGTTCCGTGTCATTGCC ATCAACGAGGTTGGGAGCAGCCACCCCAGCCTCCCATCCGAGCGCTACCGAACCAGTGGAGCACCCCCCG AGTCCAATCCTGGTGACGTGAAGGGAGAGGGGACCAGAAAGAACAACATGGAGATCACGTGGACGCCCAT GAATGCCACCTCGGCCTTTGGCCCCAACCTGCGCTACATTGTCAAGTGGAGGCGGAGAGAGACTCGAGAG GCCTGGAACAACGTCACAGTGTGGGGCTCTCGCTACGTGGTGGGGCAGACCCCAGTCTACGTGCCCTATG AGATCCGAGTCCAGGCTGAAAATGACTTCGGGAAGGGCCCTGAGCCAGAGTCCGTCATCGGTTACTCCGG AGAAGATTATCCCAGGGCTGCGCCCACTGAAGTTAAAGTCCGAGTCATGAACAGCACAGCCATCAGCCTT CAGTGGAACCGCGTCTACTCCGACACGGTCCAGGGCCAGCTCAGAGAGTACCGAGCCTACTACTGGAGGG AGAGCAGCTTGCTGAAGAACCTGTGGGTGTCTCAGAAGAGACAGCAAGCCAGCTTCCCTGGTGACCGCCT CCGTGGCGTGGTGTCCCGCCTCTTCCCCTACAGTAACTACAAGCTGGAGATGGTTGTGGTCAATGGGAGA GGTGATGGGCCTCGCAGTGAGACCAAGGAGTTCACCACCCCGGAAGGAGTACCCAGTGCCCCTAGGCGTT TCCGAGTCCGGCAGCCCAACCTGGAGACAATCAACCTGGAATGGGATCATCCTGAGCATCCAAATGGGAT CATGATTGGATACACTCTCAAATATGTGGCCTTTAACGGGACCAAAGTAGGAAAGCAGATAGTGGAAAAC TTCTCTCCCAATCAGACCAAGTTCACGGTGCAAAGAACGGACCCCGTGTCACGCTACCGCTTTACCCTCA GCGCCAGGACGCAGGTGGGCTCTGGGGAAGCCGTCACAGAGGAGTCACCAGCACCCCCGAATGAAGCTTA CACCAACAACCAAGCGGACATCGCCACCCAGGGCTGGTTCATTGGGCTTATGTGCGCCATCGCCCTCCTG GTGCTGATCCTGCTCATCGTCTGTTTCATCAAGAGGAGTCGCGGCGGCAAGTACCCAGTACGAGAAAAGA AGGATGTTCCCCTTGGCCCTGAAGACCCCAAGGAAGAGGATGGCTCATTTGACTATAGTGATGAGGACAA CAAGCCCCTGCAGGGCAGTCAGACATCTCTGGACGGCACCATCAAGCAGCAGGAGAGTGACGACAGCCTG GTGGACTATGGCGAGGGTGGCGAGGGTCAGTTCAATGAAGACGGCTCCTTCATCGGCCAGTACACGGTCA AAAAGGACAAGGAGGAAACAGAGGGCAACGAAAGCTCAGAGGCCACGTCACCTGTCAATGCTATCTACTC TCTGGCC ACGCGTACGCGGCCGCTCGAG - GFP Tag - GTTTAA >RG214686 representing NM_015090
Red=Cloning site Green=Tags(s) MARQPPPPWVHAAFLLCLLSLGGAIEIPMDLTQPPTITKQSAKDHIVDPRDNILIECEAKGNPAPSFHWT RNSRFFNIAKDPRVSMRRRSGTLVIDFRSGGRPEEYEGEYQCFARNKFGTALSNRIRLQVSKSPLWPKEN LDPVVVQEGAPLTLQCNPPPGLPSPVIFWMSSSMEPITQDKRVSQGHNGDLYFSNVMLQDMQTDYSCNAR FHFTHTIQQKNPFTLKVLTNHPYNDSSLRNHPDMYSARGVAERTPSFMYPQGTASSQMVLRGMDLLLECI ASGVPTPDIAWYKKGGDLPSDKAKFENFNKALRITNVSEEDSGEYFCLASNKMGSIRHTISVRVKAAPYW LDEPKNLILAPGEDGRLVCRANGNPKPTVQWMVNGEPLQSAPPNPNREVAGDTIIFRDTQISSRAVYQCN TSNEHGYLLANAFVSVLDVPPRMLSPRNQLIRVILYNRTRLDCPFFGSPIPTLRWFKNGQGSNLDGGNYH VYENGSLEIKMIRKEDQGIYTCVATNILGKAENQVRLEVKDPTRIYRMPEDQVARRGTTVQLECRVKHDP SLKLTVSWLKDDEPLYIGNRMKKEDDSLTIFGVAERDQGSYTCVASTELDQDLAKAYLTVLGRPDRPRDL ELTDLAERSVRLTWIPGDANNSPITDYVVQFEEDQFQPGVWHDHSKYPGSVNSAVLRLSPYVNYQFRVIA INEVGSSHPSLPSERYRTSGAPPESNPGDVKGEGTRKNNMEITWTPMNATSAFGPNLRYIVKWRRRETRE AWNNVTVWGSRYVVGQTPVYVPYEIRVQAENDFGKGPEPESVIGYSGEDYPRAAPTEVKVRVMNSTAISL QWNRVYSDTVQGQLREYRAYYWRESSLLKNLWVSQKRQQASFPGDRLRGVVSRLFPYSNYKLEMVVVNGR GDGPRSETKEFTTPEGVPSAPRRFRVRQPNLETINLEWDHPEHPNGIMIGYTLKYVAFNGTKVGKQIVEN FSPNQTKFTVQRTDPVSRYRFTLSARTQVGSGEAVTEESPAPPNEAYTNNQADIATQGWFIGLMCAIALL VLILLIVCFIKRSRGGKYPVREKKDVPLGPEDPKEEDGSFDYSDEDNKPLQGSQTSLDGTIKQQESDDSL VDYGEGGEGQFNEDGSFIGQYTVKKDKEETEGNESSEATSPVNAIYSLA TRTRRLE - GFP Tag - V |
| Restriction Sites |
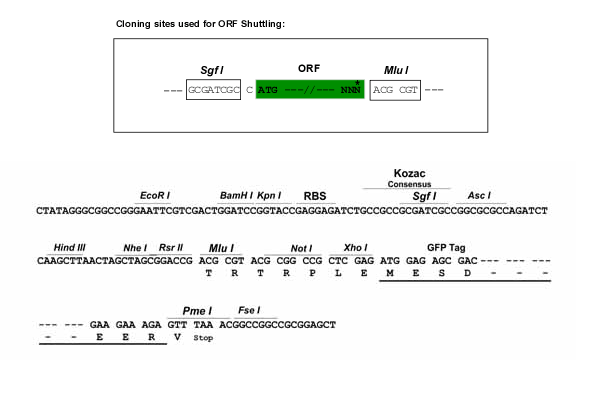
SgfI-MluI
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_015090 |
| ORF Size | 3507 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Reference Data | |
| RefSeq | NM_015090.3, NP_055905.2 |
| RefSeq Size | 10138 |
| RefSeq ORF | 3510 |
| Locus ID | 23114 |
| Protein Families | Transmembrane |
| Protein Pathways | Cell adhesion molecules (CAMs) |
| Gene Summary | This gene encodes an L1 family immunoglobulin cell adhesion molecule with multiple IGcam and fibronectin domains. The protein functions in neurite outgrowth, neurite fasciculation, and organization of the axon initial segment (AIS) and nodes of Ranvier on axons during early development. Both the AIS and nodes of Ranvier contain high densities of voltage-gated Na+ (Nav) channels which are clustered by interactions with cytoskeletal and scaffolding proteins including this protein, gliomedin, ankyrin 3 (ankyrin-G), and betaIV spectrin. This protein links the AIS extracellular matrix to the intracellular cytoskeleton. This gene undergoes extensive alternative splicing, and the full-length nature of some variants has not been determined. [provided by RefSeq, May 2009] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
{0} Product Review(s)
0 Product Review(s)
Submit review
Be the first one to submit a review

Product Citations
*Delivery time may vary from web posted schedule. Occasional delays may occur due to unforeseen
complexities in the preparation of your product. International customers may expect an additional 1-2 weeks
in shipping.