


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Caspr (CNTNAP1) (NM_003632) Human Tagged ORF Clone
CAT#: RC218019

CNTNAP1 (Myc-DDK-tagged)-Human contactin associated protein 1 (CNTNAP1)
"NM_003632" in other vectors (6)
Product Images
 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC218019 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | CNTNAP1 |
| Synonyms | CASPR; CHN3; CNTNAP; NRXN4; P190 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC218019 representing NM_003632
Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGATGCATCTCCGGCTCTTCTGCATCCTGCTCGCCGCGGTCTCAGGAGCCGAGGGCTGGGGCTACTACG GCTGCGACGAGGAGCTGGTGGGTCCCCTGTATGCACGCTCCCTGGGCGCCTCCTCCTACTACAGTCTCCT TACTGCGCCGCGATTCGCCAGGCTGCACGGCATAAGCGGGTGGTCACCACGGATTGGGGATCCGAATCCC TGGCTCCAGATAGACTTAATGAAGAAGCACCGGATCCGGGCCGTGGCCACACAGGGCTCCTTTAATTCTT GGGACTGGGTCACACGTTACATGCTACTCTACGGCGACCGAGTGGACAGCTGGACACCGTTCTACCAGCG AGGGCACAACTCGACCTTCTTTGGTAACGTGAACGAGTCGGCGGTGGTGCGCCATGACCTGCACTTCCAC TTCACTGCGCGCTACATCCGCATCGTGCCCCTGGCCTGGAACCCACGCGGCAAGATCGGCCTGAGGCTCG GCCTCTATGGCTGCCCATACAAGGCCGACATACTCTATTTCGACGGCGACGATGCCATCTCCTACCGCTT CCCGCGAGGGGTCAGCCGAAGCCTGTGGGACGTGTTCGCCTTCAGCTTCAAGACCGAGGAGAAGGACGGT CTTCTGCTGCACGCCGAGGGCGCCCAGGGCGACTACGTGACGCTCGAGCTGGAGGGGGCACACCTGCTGC TGCACATGAGCCTGGGCAGCAGCCCTATCCAGCCAAGACCAGGTCACACCACCGTGAGCGCAGGCGGAGT CCTCAATGACCAGCACTGGCACTATGTGCGGGTGGACCGATTTGGCCGCGATGTAAATTTCACCCTGGAC GGCTATGTGCAGCGCTTTATTCTCAATGGAGACTTCGAGAGGCTGAACCTGGACACTGAGATGTTCATCG GAGGTCTGGTGGGCGCCGCGCGGAAGAACCTGGCCTATCGGCATAACTTCCGCGGCTGCATAGAAAACGT AATCTTCAACCGCGTCAACATCGCAGACCTGGCCGTGCGGCGCCATTCCCGGATCACCTTCGAGGGTAAG GTGGCTTTTCGTTGCCTGGACCCGGTACCGCACCCTATCAACTTCGGAGGCCCTCACAACTTCGTTCAAG TGCCCGGTTTCCCACGCCGTGGCCGCCTGGCAGTCTCATTTCGCTTCCGCACCTGGGACCTCACCGGGCT TCTCCTTTTCTCCCGTCTGGGGGACGGGCTGGGCCACGTGGAGCTGACGCTCAGCGAAGGGCAGGTCAAC GTGTCCATCGCGCAGAGCGGCCGAAAGAAGCTTCAGTTCGCTGCTGGGTACCGACTGAATGACGGCTTTT GGCACGAGGTGAATTTTGTGGCACAGGAAAACCATGCAGTTATCAGCATTGATGATGTGGAAGGGGCAGA GGTCAGGGTCTCATACCCGTTGCTGATCCGGACAGGGACCTCATATTTCTTTGGGGGTTGTCCCAAGCCA GCCAGTCGATGGGACTGCCACTCCAACCAGACGGCATTCCATGGCTGCATGGAGCTGCTCAAGGTGGATG GTCAACTGGTCAACCTGACTCTGGTGGAGGGCCGGCGGCTTGGATTCTATGCTGAGGTCCTCTTTGATAC ATGTGGCATCACTGATAGGTGCAGCCCTAACATGTGTGAGCATGATGGACGCTGCTACCAGTCTTGGGAT GACTTCATTTGCTACTGCGAACTGACGGGCTACAAGGGAGAGACCTGCCACACACCTTTGTATAAGGAAT CCTGTGAGGCTTATCGGCTCAGTGGGAAAACTTCTGGAAACTTCACCATTGATCCTGATGGCAGTGGCCC CCTGAAGCCATTTGTAGTGTACTGTGATATCCGAGAGAACCGAGCGTGGACAGTTGTGCGGCATGACAGG CTGTGGACAACTCGAGTGACAGGTTCCAGCATGGAGCGGCCATTCCTGGGGGCTATCCAGTACTGGAATG CATCCTGGGAGGAAGTCAGTGCCCTTGCCAATGCTTCCCAGCATTGTGAACAGTGGATCGAGTTCTCCTG CTACAATTCCCGGCTGCTCAACACTGCAGGAGGCTACCCCTACAGCTTTTGGATTGGCCGAAATGAGGAG CAGCACTTCTACTGGGGAGGCTCCCAGCCTGGGATCCAGCGCTGTGCCTGTGGTCTGGACCGGAGCTGTG TGGACCCTGCCTTGTACTGCAACTGTGACGCTGACCAGCCCCAGTGGAGAACTGACAAGGGACTGCTGAC CTTTGTGGACCATCTGCCTGTCACTCAGGTAGTGATAGGGGATACGAACCGCTCCACTTCTGAGGCCCAG TTCTTCCTGAGGCCTCTGCGCTGCTATGGCGATCGAAATTCCTGGAACACCATTTCCTTCCACACCGGGG CTGCACTACGCTTCCCCCCAATCCGTGCCAACCACAGCCTGGATGTCTCCTTCTACTTCAGGACCTCTGC TCCCTCGGGGGTCTTCCTAGAGAATATGGGGGGCCCTTACTGCCAGTGGCGCCGACCTTATGTGCGGGTG GAACTCAACACATCCCGGGATGTGGTCTTCGCCTTTGATGTGGGGAATGGGGATGAGAACCTCACAGTAC ACTCAGACGACTTTGAGTTCAATGATGACGAGTGGCACCTGGTCCGGGCTGAAATCAACGTGAAGCAGGC CCGGCTCCGAGTGGATCACCGGCCCTGGGTTCTGCGGCCTATGCCACTGCAGACCTACATCTGGATGGAG TATGACCAGCCCCTCTATGTGGGATCTGCAGAGCTTAAGAGACGCCCCTTTGTGGGTTGCTTGAGGGCCA TGCGTCTGAACGGAGTGACTCTGAACCTGGAGGGCCGTGCCAATGCCTCTGAGGGTACCTCACCCAACTG CACAGGCCACTGTGCCCACCCTCGGCTCCCCTGTTTCCATGGAGGCCGCTGCGTGGAGCGCTATAGCTAC TACACGTGTGACTGTGACCTCACGGCTTTTGATGGGCCATACTGCAACCACGATATTGGTGGTTTCTTTG AGCCGGGCACCTGGATGCGCTATAACCTACAGTCAGCGCTGCGCTCTGCAGCCAGGGAGTTCTCCCACAT GCTGAGCCGGCCAGTGCCAGGCTATGAGCCTGGCTACATCCCGGGCTATGATACTCCGGGCTATGTGCCT GGCTACCATGGCCCCGGGTACCGCCTGCCCGACTACCCCCGGCCTGGTCGGCCTGTGCCCGGTTACCGTG GGCCTGTCTACAACGTTACGGGAGAGGAGGTCTCCTTCAGCTTCAGCACCAGCTCCGCCCCTGCTGTCCT GCTCTACGTCAGTTCCTTTGTTCGTGACTACATGGCTGTGCTCATCAAGGATGATGGGACCCTTCAGCTG CGATATCAGCTGGGCACCAGTCCCTACGTGTACCAGCTAACCACTCGACCAGTGACCGATGGCCAGCCCC ATAGCATCAATATCACCCGTGTTTACCGGAACCTCTTCATCCAGGTGGACTACTTCCCACTGACAGAGCA GAAGTTCTCGCTGTTGGTGGACAGCCAGTTGGACTCACCCAAGGCCTTGTATTTAGGGCGTGTGATGGAG ACAGGAGTCATTGACCCGGAGATCCAGCGCTACAACACCCCAGGTTTCTCAGGCTGCCTGTCTGGTGTTC GATTCAACAACGTGGCTCCCCTCAAGACCCACTTCCGAACCCCTCGACCCATGACTGCTGAGCTAGCTGA GGCCCTTCGAGTTCAGGGAGAACTGTCCGAATCTAATTGCGGAGCTATGCCACGTCTTGTTTCAGAGGTG CCACCTGAGCTTGATCCCTGGTATCTGCCCCCAGACTTCCCCTACTACCATGATGAAGGATGGGTTGCCA TACTTTTAGGCTTTTTGGTGGCCTTTCTGCTGCTGGGGCTGGTGGGAATGTTGGTGCTCTTCTATCTGCA AAATCATCGCTATAAGGGCTCCTACCATACCAATGAGCCCAAGGCTGCCCACGAGTACCATCCTGGCAGC AAACCTCCCCTACCCACTTCAGGCCCTGCCCAGGTCCCCACCCCTACAGCAGCTCCCAACCAAGCTCCAG CCTCAGCCCCAGCCCCAGCCCCAACTCCAGCCCCAGCCCCTGGCCCCCGGGATCAGAACCTACCCCAGAT CCTGGAGGAGTCCAGGTCTGAA ACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCCTGGATT ACAAGGATGACGACGATAAGGTTTAA >RC218019 representing NM_003632
Red=Cloning site Green=Tags(s) MMHLRLFCILLAAVSGAEGWGYYGCDEELVGPLYARSLGASSYYSLLTAPRFARLHGISGWSPRIGDPNP WLQIDLMKKHRIRAVATQGSFNSWDWVTRYMLLYGDRVDSWTPFYQRGHNSTFFGNVNESAVVRHDLHFH FTARYIRIVPLAWNPRGKIGLRLGLYGCPYKADILYFDGDDAISYRFPRGVSRSLWDVFAFSFKTEEKDG LLLHAEGAQGDYVTLELEGAHLLLHMSLGSSPIQPRPGHTTVSAGGVLNDQHWHYVRVDRFGRDVNFTLD GYVQRFILNGDFERLNLDTEMFIGGLVGAARKNLAYRHNFRGCIENVIFNRVNIADLAVRRHSRITFEGK VAFRCLDPVPHPINFGGPHNFVQVPGFPRRGRLAVSFRFRTWDLTGLLLFSRLGDGLGHVELTLSEGQVN VSIAQSGRKKLQFAAGYRLNDGFWHEVNFVAQENHAVISIDDVEGAEVRVSYPLLIRTGTSYFFGGCPKP ASRWDCHSNQTAFHGCMELLKVDGQLVNLTLVEGRRLGFYAEVLFDTCGITDRCSPNMCEHDGRCYQSWD DFICYCELTGYKGETCHTPLYKESCEAYRLSGKTSGNFTIDPDGSGPLKPFVVYCDIRENRAWTVVRHDR LWTTRVTGSSMERPFLGAIQYWNASWEEVSALANASQHCEQWIEFSCYNSRLLNTAGGYPYSFWIGRNEE QHFYWGGSQPGIQRCACGLDRSCVDPALYCNCDADQPQWRTDKGLLTFVDHLPVTQVVIGDTNRSTSEAQ FFLRPLRCYGDRNSWNTISFHTGAALRFPPIRANHSLDVSFYFRTSAPSGVFLENMGGPYCQWRRPYVRV ELNTSRDVVFAFDVGNGDENLTVHSDDFEFNDDEWHLVRAEINVKQARLRVDHRPWVLRPMPLQTYIWME YDQPLYVGSAELKRRPFVGCLRAMRLNGVTLNLEGRANASEGTSPNCTGHCAHPRLPCFHGGRCVERYSY YTCDCDLTAFDGPYCNHDIGGFFEPGTWMRYNLQSALRSAAREFSHMLSRPVPGYEPGYIPGYDTPGYVP GYHGPGYRLPDYPRPGRPVPGYRGPVYNVTGEEVSFSFSTSSAPAVLLYVSSFVRDYMAVLIKDDGTLQL RYQLGTSPYVYQLTTRPVTDGQPHSINITRVYRNLFIQVDYFPLTEQKFSLLVDSQLDSPKALYLGRVME TGVIDPEIQRYNTPGFSGCLSGVRFNNVAPLKTHFRTPRPMTAELAEALRVQGELSESNCGAMPRLVSEV PPELDPWYLPPDFPYYHDEGWVAILLGFLVAFLLLGLVGMLVLFYLQNHRYKGSYHTNEPKAAHEYHPGS KPPLPTSGPAQVPTPTAAPNQAPASAPAPAPTPAPAPGPRDQNLPQILEESRSE TRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
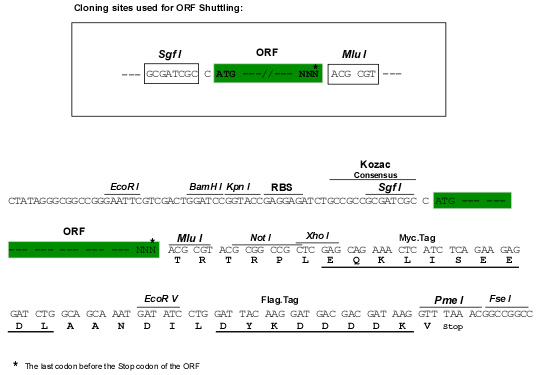
| Restriction Sites |
SgfI-MluI
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_003632 |
| ORF Size | 4152 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified, transfection-ready dried plasmid DNA, and shipped with 2 vector sequencing primers. |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_003632.1, NM_003632.2, NP_003623.1 |
| RefSeq Size | 5293 bp |
| RefSeq ORF | 4155 bp |
| Locus ID | 8506 |
| Domains | F5_F8_type_C, LamG, EGF |
| Protein Families | Druggable Genome, Transmembrane |
| Protein Pathways | Cell adhesion molecules (CAMs) |
| MW | 156.27 kDa |
| Gene Summary | The gene product was initially identified as a 190-kD protein associated with the contactin-PTPRZ1 complex. The 1,384-amino acid protein, also designated p190 or CASPR for 'contactin-associated protein,' includes an extracellular domain with several putative protein-protein interaction domains, a putative transmembrane domain, and a 74-amino acid cytoplasmic domain. Northern blot analysis showed that the gene is transcribed predominantly in brain as a transcript of 6.2 kb, with weak expression in several other tissues tested. The architecture of its extracellular domain is similar to that of neurexins, and this protein may be the signaling subunit of contactin, enabling recruitment and activation of intracellular signaling pathways in neurons. [provided by RefSeq, Jan 2009] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| SC117823 | CNTNAP1 (untagged)-Human contactin associated protein 1 (CNTNAP1) |
USD 2,800.00 |
|
| RG218019 | CNTNAP1 (GFP-tagged) - Human contactin associated protein 1 (CNTNAP1) |
USD 1,250.00 |
|
| RC218019L1 | Lenti ORF clone of Human contactin associated protein 1 (CNTNAP1), Myc-DDK-tagged |
USD 1,656.00 |
|
| RC218019L2 | Lenti ORF clone of Human contactin associated protein 1 (CNTNAP1), mGFP tagged |
USD 1,340.00 |
|
| RC218019L3 | Lenti ORF clone of Human contactin associated protein 1 (CNTNAP1), Myc-DDK-tagged |
USD 1,656.00 |
|
| RC218019L4 | Lenti ORF clone of Human contactin associated protein 1 (CNTNAP1), mGFP tagged |
USD 1,340.00 |
{0} Product Review(s)
Be the first one to submit a review

